日常开发笔记
jupyter notebook 格式化
title
1 | |
script
1 | |
math
1 | |
Git 相关
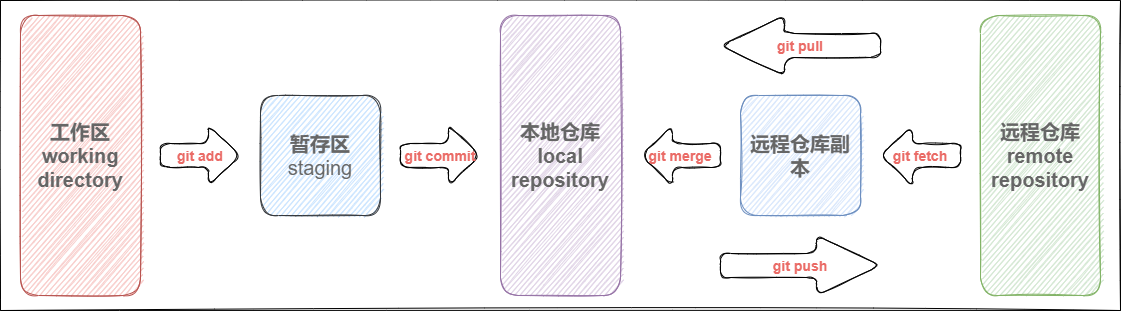
相关命令
分支
git 回退本地修改
1
2git checkout <filename>
git checkout .切换到分支
1
2git checkout <branch> # 切换到 <branch> 分支
git checkout -b <branch> # 创建 <branch> 分支并切换到该分支删除分支
删除本地分支
1
git branch -d <branch>删除远程分支
1
git push origin -d <branch>
清空 git 缓存
1
git rm -r --cached .日志
1
git log-<n>:显示日志(q 退出),显示 n 条日志--stat:每个提交都列出了修改过的文件,以及其中添加和移除的行数,并在最后列出所有增减行数author:显示指定作者的提交--grep:过滤提交说明中的文字--<path>:如果只关心某个文件或者目录的历史提交,可以在git log最后指定路径
比较工作区和上个提交版本的区别
1
git diff <filename>拉取
1
2
3git fetch # 拉取所有分支的变化
git fetch -p # 拉取所有分支的变化,并将远端不存在的分支同步移除
git fetch <origin master> # 拉取指定分支的变化回滚
1
2git reset # 将提交记录回滚,代码不回滚
git reset --hard # 将提交记录和代码全部回滚- stash
1
2
3
4git stash # 将当前工作区的状态存储下来
git stash list # 查看当前有多少 stash
git stash apply --index # 把某一个 stash 应用回当前的分支
git stash -include-untracked # 有些文件没有在 git 的 track 里,可以添加参数来存储对应的文件- 用
git stash apply命令恢复,但是恢复后,stash内容并不删除,需要用git stash drop来删除 - 用
git stash pop命令,恢复的同时把 stash 存储列表的内容也删除
- 用
查看某个 hash 所对应的 object 中的内容
1
git cat-file -p <commit_id>丢弃本地修改的所有文件(新增、删除、修改)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20git checkout . # 本地所有修改的。没有的提交的,都返回到原来的状态
git stash # 把所有没有提交的修改暂存到 stash 里面。可用 git stash pop 回复
git reset --hard HASH # 返回到某个节点,不保留修改,已有的改动会丢失
git reset --soft HASH # 返回到某个节点,保留修改,已有的改动会保留,在未提交中,git status 或 git diff 可看
git clean -df # 返回到某个节点,(未跟踪文件的删除)
git clean 参数
# -n 不实际删除,只是进行演练,展示将要进行的操作,有哪些文件将要被删除。(可先使用该命令参数,然后再决定是否执行)
# -f 删除文件
# -i 显示将要删除的文件
# -d 递归删除目录及文件(未跟踪的)
# -q 仅显示错误,成功删除的文件不显示
注:
git reset # 删除的是已跟踪的文件,将已 commit 的回退
git clean # 删除的是未跟踪的文件
git clean -nxdf # 查看要删除的文件及目录,确认无误后再使用下面的命令进行删除
git checkout . && git clean -xdf
Hexo 部署的博客 Git 提交到 Github 账户错乱的问题
由于通过 SmartGit 设置了 全局的用户名 和全局的邮箱(工作用的 Git 账号和邮箱)导致提交到 Github 上的版本不是自己的账户
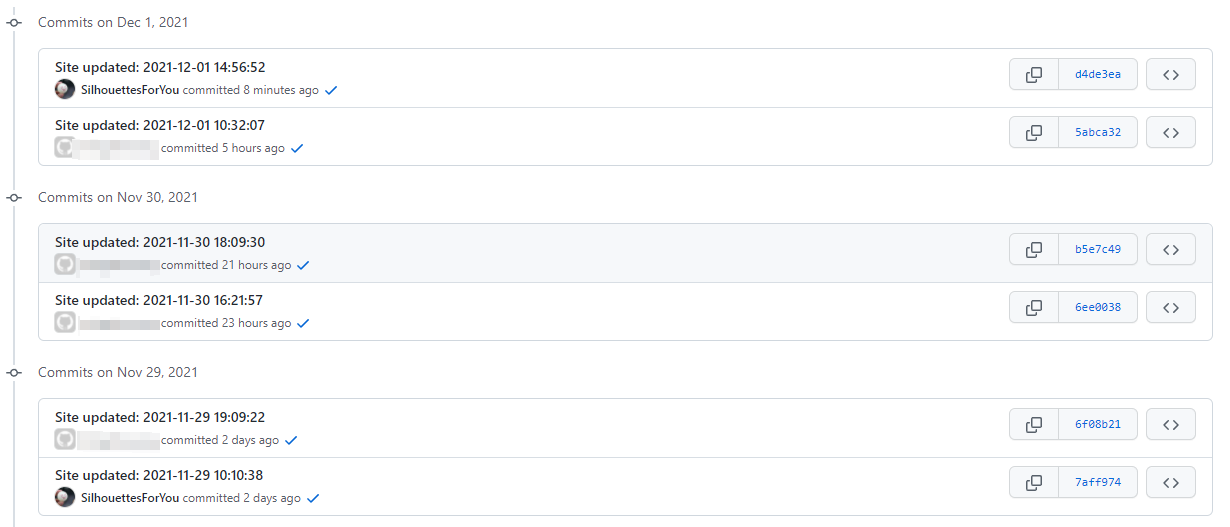
解决方法
在博客目录下找到 .deploy_git 目录(没有的话用 hexo g 生成一下就可以),然后可以看到当前目录的用户名和邮箱与自己的不一致,通过以下命令可以更改为一致的用户名和邮箱:
1 | |
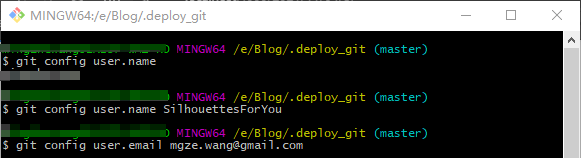
之后再进行博客的 发布 便可以用正确的用户提交到 Github
Git 文件目录结构解析
1 | |
Git 切换远端分支
查看所有分支
1 | |
git branch不带参数,列出本地已经存在的分支,并且在当前分支的前面用*标记,加上 -a 参数可以查看所有分支列表,包括本地和远程,远程分支一般会用红色字体标记出来
如果用git branch -a没有显示全部的远程分支,可以通过git fetch将本地远程跟踪分支进行更新,与远程分支保持一致
新建分支并切换到指定分支
1 | |
该命令可以将远程 git 仓库里的指定分支拉取到本地,这样就在本地新建了一个 feature_4it01_skilltesttools 分支,并和指定的远程分支 origin/feature_4it01_skilltesttools 关联了起来。
查看本地分支及追踪的分支
1 | |
*表示当前所在分支,[远程分支] 表示当前本地分支追踪的远程分支,最后一个是最近一次提交的注释。
git cherry-pick用法
对于多分支的代码库,将代码从一个分支转移到另一个分支是常见需求。如果需要另一个分支的所有代码变动,那么就采用 git merge;如果只需要部分代码变动(某几个提交),这时可以采用git cherry-pick,它的功能是把已经存在的commit 进行挑选,然后重新提交。
转移一个提交
- 先切换到 A 分支
git checkout A - 找到这次提交
git log,赋值<hash code> - 再切换到 B 分支
git chekcou B - 把 A 分支下的至此提交重新提交到 B 分支下
git cherrt-pick <hash code>
当执行完 git cherry-pick以后,将会生成一个新的提交,这个新的提交的 hash 值和原来的不同,但标志名称一样。
转移多个提交
1 | |
Unity 相关
几种 Update 方法的区别
Update
Update 是在每次渲染新的一帧的时候才会调用
FixedUpdate
该函数用于固定更新,在游戏运行的过程中,每一帧的处理时间是不固定的,当需要固定间隔时间执行某些代码时,就会用到 FixedUpdate() 函数
LastUpdate
该函数是延迟更新函数,处于激活状态虾的脚本在每一帧里都会在 Update() 函数执行后调用该函数,通常用来调正代码执行的顺序。比如玩家的角色需要一个摄像机来跟随,那么通常角色的移动逻辑会写在 Update() 里,而摄像机跟随写在 LastUpdate() 里。这样可以确保在角色的位置计算完毕后,再根据角色位置确定摄像机的位置和视角
Unity3D 内存管理——对象池(Object Pool)
1 | |
ObjectPool使用了一个栈(后进先出的数据结构),当需要新建(Get)一个新的对象的时候先从栈顶取出第一个,当使用结束的时候将其释放掉(Relaease),就是将其重新放回栈里面,而不是每次都实例化一个新的对象。
协程
协程不是线程,不是异步执行。协程和 MonoBehaviour 的Update函数一样在主线程中执行,Unity 在每一帧都会处理对象上的协程。
协程的执行原理
IEnumberator
协程函数的返回值时IEnumberator,它是一个迭代器,可以把它当成执行一个序列的某个节点的指针。它 3 个方法,分别是
Current:返回当前指向的元素MoveNext:将指针向后移动一个单位,如果移动成功,则返回trueReset:把位置重置为初始状态
yield
yield关键字用来声明序列中的下一个值或者是一个无意义的值。
当用 yield return x(x 是指一个具体的对象或数值)挂起协程:MoveNext返回为 true,Current 被赋值为 x;当用yield break 挂起协程,MoveNext返回为 false。 如果 MoveNext 函数返回为 true 意味着协程的执行条件被满足,则能够从当前位置继续往下执行,否则不能从当前位置继续往下执行。只有当 MoveNext 返回 false 时,才会执行 yield return 后面的语句。
中断函数类型
| 语句 | 含义 |
|---|---|
yield return null/yield return 0; |
程序在下一帧中从当前位置继续执行 |
yield return new WaitForSeconds(N); |
程序等待 N 秒后从当前位置继续执行 |
yield new WaitForEndOfFrame(); |
在所有的渲染以及 GUI 程序执行完成后从当前位置继续执行 |
yield new WaitForFixedUpdate(); |
所有脚本中的 FixedUpdate() 函数都被执行后从当前位置继续执行 |
yield return WWW; |
等待一个网络请求完成后从当前位置继续执行 |
yield return StartCoroutine(xxx); |
等待一个 xxx 的协程执行完成后从当前位置继续执行 |
yield break; |
跳出协程 |
What is the difference between “yield return 0” and “yield return null” in Coroutine
Both
yield return 0andyield return nullyields for a single frame. The biggest difference is thatyield return 0allocates memory because of boxing and unboxing of the0that happens under the hood, butyield return nulldoes not allocate memory. Because of this, it is highly recommended to useyield return nullif you care about performance.
Unity EditorWindow 的 OnGUI 刷新
在编辑器模式下,OnGUI只有在窗口激活的状态(即鼠标移动到窗口上、点击事件等)才会刷新,执行OnGUI。如果需要实时刷新的话,可用 OnInspectorUpdate 开启窗口重绘,Unity 会每秒 10 帧重绘窗口。
C# 相关
C# 泛型约束
在定义泛型类时。可以对代码能够在实例化类时用于类型参数的类型种类加限制。如果代码尝试使用某个约束所不允许的类型来实例化类,则会产生编译错误。这些限制成为约束,约束是使用 where 上下文关键字指定的。
| 约束 | 说明 |
|---|---|
T : struct |
类型参数碧血是值类型,可以指定除 Nullable 以外的任何值类型 |
T : class |
类型参数必须是引用类型,包括任何类、接口、委托或数组类型 |
T : new() |
类型参数必须具有无参数的公共构造函数,当与其他约束一起使用时,new()约束必须最后指定 |
T : < 基类名 > |
类型参数必须是指定的基类或派生自指定的基类 |
T : < 接口名 > |
类型参数必须是指定的接口或实现指定的接口,可以指定多个接口约束,接口约束也可以是泛型的 |
T : U |
为 T 提供的类型参数必须是为 U 提供的参数或派生自为 U 提供的参数,这成为裸类型约束 |
default函数
default(T) 可以得到该类型的默认值,C# 在初始化时,会给未显示肤质的字段、属性赋上默认值,但值变量却不会,值变量可以使用默认构造函数赋值,或者使用 default(T) 赋值。
| 值类型 | 默认值 |
|---|---|
bool |
false |
byte/int/sbyte /short /uint /ulong /ushort |
0 |
decimal |
0.0M |
double |
0.0D |
float |
0.0F |
long |
0L |
enum |
表达式 (E)0 产生的值,其中 E 为enum标识符 |
struct |
将所有的值类型字段设置为默认值并将所有的引用类型字段设置为 null 时产生的值 |
| 引用类型 | null |
C# 中 is,as,using 关键字的使用
is:用于检查对象是否与给定类型兼容,不会抛出异常as:用于引用类型之间转换,直接进行转换,若转换成功,则返回转换后的对象,若转换失败则返回null,不会抛出异常using:引用命名空间,有效回收资源,using关键字可以回收多个对象的资源,关键字后面的小括号内创建的对象必须实现IDisposanble接口,或者该类的基类已经实现了IDisposable接口。回收资源的时机是在using关键字下面的代码块执行完成之后自动调用接口方法Dispose()销毁对象
ref和 out 关键字
C# 的数据类型有两种:一种是值类型(value type),一种是引用类型(reference type)。
- 值类型:结构体(数值类型,
bool,用户自定义结构体)、枚举和可空类型。 - 引用类型:数组、用户定义的类、接口、委托、
object、字符串。
值类型和引用类型的区别在于:函数传递的时候,值类型把自己的值复制一份传递给别的函数;引用类型则是把自己的地址传递给函数。
ref和 out 都是按地址传递的,使用后都将改变原来参数的数值。ref可以把参数的数值传递进函数,传递到 ref 参数必须初始化,否则会报错;但是 out 是要把参数清空,无法把一个数值从 out 传递进去,传递进去后必须初始化一次。
C# 特性标签(Attribute)
公共语言运行时能够添加类似于关键字的描述性声明称为特性,以便批注编程元素(如类型、字段、方法和属性)。将特性与程序实体相关联后,可以在运行时使用 反射 查询特性。
可以将特性附加到几乎任何声明中。在 C# 中,通过用方括号([])将特性名称括起来,并置于应用该特性的实体的声明上方以指定特性。
创建自定义特性
可以通过定义特性类创建自定义特性,特性类是直接或间接派生自 Attribute 的类,可快速轻松地识别元数据中的特性定义。
1 | |
访问特性
对于自定义特性,可以用 Type 中的 IsDefined 和GetCustomAttributes方法来获取。
IsDefined:public abstract bool IsDefined(Type attributeType, bool inherit),用来加测某个特性是否应用到某个类上GetCustomAttributes:public abstract object[] GetCustomAttributes(bool inherit),调用它后,会创建一个与目标相关联的特性的实例
特性与注释的区别
注释是对程序源代码的一种说明,程序编译的时候会忽略它,而特性是代码的一部分,它会被编译器编译进程序的元数据里,在程序运行的时候,随时可以从元数据中提取出这些附加信息。
Action委托与 Func 委托
Action 不能指向有返回值的方法,不能有返回值。Func可以指向有一个返回值的方法,且必须有返回值。
Activator.CreateInstance<T>与 new
new 和Activator.CreateInstance都用于实例化一个类,Activator.CreateInstance使用与指定参数匹配程度最高的构造函数来创建指定类型的实例。
1 | |
编译器会将 return new T() 转换调用 Actuvator.CreateInstance 方法。
C# 资源回收和 IDisposable 接口的使用
托管资源和非托管资源
- 托管资源由 CLR 来维护,自动进行垃圾回收,比如数组
- 非托管资源不会进行自动垃圾回收,需要手动释放,比如句柄。但在 c# 中的非托管资源很多都被封装到 .NET 类中,当对象释放时内部方法同时释放非托管资源
在 C# 中创建的对象,数组,列表等等都不需要考虑资源释放的问题,因为它会被 CLR 的垃圾回收机制自动回收。创建的对象释放时是随机的不确定时长的等待自动回收机制进行收回,有没有办法主动回收这些资源呢,比如对象占用内存较大,想主动立即释放而不等待主动回收。可以写一个方法,在这个方法里释放引用的资源就可以了,这个方法可以随便起名,当然更规范的是继承 IDisposable 来实现 Disposable 方法。
C# 中数组、ArrayList和 List 三者的区别
数组
数组在 C# 中最早出现的。在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单。但是数组存在一些不足的地方。在数组的两个数据间插入数据是很麻烦的,而且在声明数组的时候必须指定数组的长度,数组的长度过长,会造成内存浪费,过段会造成数据溢出的错误。如果在声明数组时我们不清楚数组的长度,就会变得很麻烦。
ArrayList
ArrayList是命名空间 System.Collections 下的一部分,在使用该类时必须进行引用,同时继承了 IList 接口,提供了数据存储和检索。ArrayList对象的大小是按照其中存储的数据来动态扩充与收缩的。所以,在声明 ArrayList 对象时并不需要指定它的长度。
1 | |
在 ArrayList 中,不仅插入了字符串,而且插入了数字。这样在 ArrayList 中插入不同类型的数据是允许的。因为 ArrayList 会把所有插入其中的数据当作为 object 类型来处理,在使用 ArrayList 处理数据时,很可能会报类型不匹配的错误,也就是 ArrayList 不是类型安全的 。在存储或检索值类型时通常发生 装箱 和拆箱 操作,带来很大的性能耗损。
泛型 List
因为 ArrayList 存在不安全类型与装箱拆箱的缺点,所以出现了泛型的概念。List类是 ArrayList 类的泛型等效类,它的大部分用法都与 ArrayList 相似,因为 List 类也继承了 IList 接口。最关键的区别在于,在声明 List 集合时,同时需要为其声明 List 集合内数据的对象类型。
Lambda 表达式
使用 Lambda 表达式来创建匿名函数。 使用 lambda 声明运算符=> 从其主体中分离 lambda 参数列表。Lambda 表达式可采用以下任意一种形式:
表达式 lambda,表达式为其主体:
1
(input-parameters) => expression语句 lambda,语句块作为其主体:
1
(input-parameters) => {<sequence-of-statements>}
若要创建 Lambda 表达式,需要在 Lambda 运算符左侧指定输入参数(如果有),然后在另一侧输入表达式或语句块。
C# API
| syntax | interpretation |
|---|---|
IsGenericType |
判断属性类型是否为泛型类型,如:typeof(int).IsGenericType --> Falsetypeof(List<int>).IsGenericType --> Truetypeof(Dictionary<int>).IsGenericType --> True |
C++ 相关
C++ 几个预定义的宏
__LINE__:源代码行号__FILE__:源文件名__DATE:编译日期__TIME__:编译时间__STDC:当要求程序严格遵循 ANSI C 标准时该标识被赋值为 1__cplusplus:当编写 C++ 程序时该表示被定义
Lua 相关
Lua 语法
定义字符串
1
2
3
4
5
6a= "双引号中可直接使用' 单引号 ', 但 \" 双引号 \"要转义"
b = '单引号中可直接使用" 双引号 ", 但 \' 单引号 \'要转义'
c = [[双方括号中
可以直接使用 '单引号'
和 "双引号",而且可以
换行]]格式字符串可能包含以下的转义码
%c- 接受一个数字,并将其转化为 ASCII 码表中对应的字符%d,%i- 接受一个数字并将其转化为有符号的整数格式%o- 接受一个数字并将其转化为八进制数格式%u- 接受一个数字并将其转化为无符号整数格式%x- 接受一个数字并将其转化为十六进制数格式,使用小写字母%X- 接受一个数字并将其转化为十六进制数格式,使用大写字母%e- 接受一个数字并将其转化为科学记数法格式,使用小写字母 e%E- 接受一个数字并将其转化为科学记数法格式,使用大写字母 E%f- 接受一个数字并将其转化为浮点数格式%g/%G- 接受一个数字并将其转化为%e(%E, 对应%G)及%f中较短的一种格式%q- 接受一个字符串并将其转化为可安全被 Lua 编译器读入的格式(即将该字符串添加了 ``)%s- 接受一个字符串并按照给定的参数格式化该字符串
Lua 堆栈操作
lua 和 C++ 之间的数据交互通过栈进行,栈中的数据通过索引值进行定位(若 lua 虚拟机堆栈里有
lua_gettop:int lua_gettop (lua_State *L);返回栈顶元素的索引lua_settop:void lua_settop (lua_State *L, int index);参数允许传入任何可接受的索引以及 0 。它将把堆栈的栈顶设为这个索引。如果新的栈顶比原来的大,超出部分的新元素将被填为nil。如果index为 0,把栈上所有元素移除
Lua 中的模式匹配(Pattern Matching)
character classes
| 符号 | 匹配模式 |
|---|---|
%a |
|
%c |
|
%d |
|
%l |
|
%p |
|
%s |
空白字符 |
magic characters
| 符号 | 描述 | 备注 |
|---|---|---|
() |
标记一个子模式,供后续使用,跟正则的用法类似 | |
. |
匹配所有字符 | 类似正则表达式,只不过正则表达式的,不包括回车\n |
% |
1. 可用作转义符; 2. 声明 character classess;3. 跟 () 结合用于子模式匹配:%N,N是一个数字,表示匹配第 N 个子串,例如 %1,%2, ...,跟正则表达式的1,2, ... 类似 |
|
^ |
如果处于模式开头,则表示匹配输入字符串的开始位置,如果放在 [] 中,表示取补集 |
|
$ |
表示匹配输入字符串的结尾位置,跟正则表达式的用法基本一致 | |
[] |
表示一个字符集合 | 例如 [%w_] 表示匹配字母数字和下划线,[a-f]表示匹配字母 a 到f |
+ |
||
- |
匹配前面的模式 0 次或多次,返回最短的匹配结果,模式匹配中的“非贪婪模式” | |
* |
匹配前面的模式 0 次或多次 |
function or expression needs too many registers
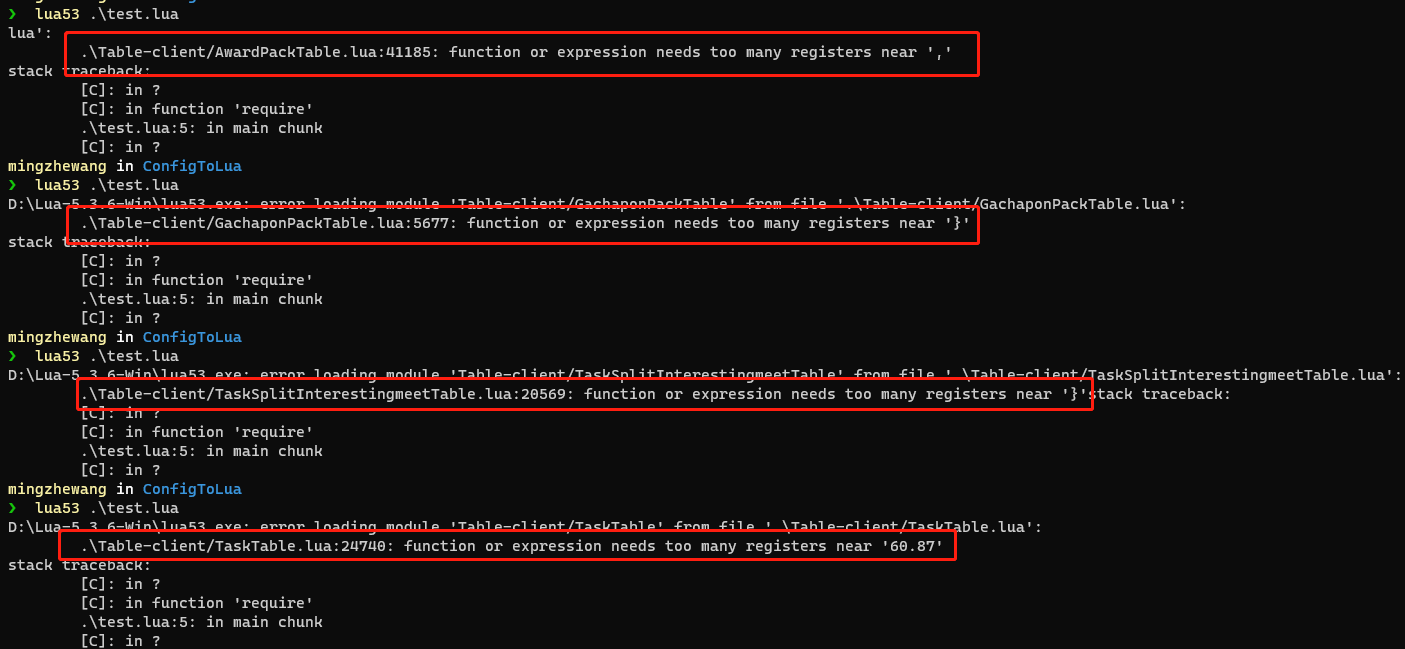
Lua 中的模块与 module 函数
编写模块的基本方法
1 | |
模块内函数之间的调用仍然要保留模块名的限定符,如果是 私有变量还需要加 local 关键字 , 同时不能加模块名限定符。可以把 test.lua 这个模块里的全局环境设置为 M,于是,我们直接定义函数的时候,不需要再带M 前缀。即:
1 | |
module函数
在 Lua 5.1 中,可以用module(...) 函数来代替,如:
1 | |
由于在默认情况下,module不提供外部访问,必须在调用它之前,为需要访问的外部函数或模块声明适当的局部变量。然后 Lua 提供了一种更为方便的实现方式,即在调用 module 函数时,多传入一个 package.seeall 的参数,相当于setmetatable(M, {__index = _G})
抵制使用 module 函数来定义 Lua 模块
旧式的模块定义方式是通过 *module("filename"[,package.seeall])*来显示声明一个包,现在官方不推荐再使用这种方式。这种方式将会返回一个由 filename 模块函数组成的 table,并且还会定义一个包含该table 的全局变量。
如果只给 module 函数一个参数(也就是文件名)的话,前面定义的全局变量就都不可用了,包括 print 函数等,如果要让之前的全局变量可见,必须在定义 module 的时候加上参数 package.seeall。调用完module 函数之后, print这些系统函数不可使用的原因,是当前的整个环境被压入栈,不再可达。
module("filename", package.seeall)这种写法仍然是不提倡的,官方给出了两点原因:
package.seeall这种方式破坏了模块的高内聚,原本引入filename模块只想调用它的foobar()函数,但是它却可以读写全局属性,例如filename.os。module函数压栈操作引发的副作用,污染了全局环境变量。例如module("filename")会创建一个filename的table,并将这个table注入全局环境变量中,这样使得没有引用它的文件也能调用filename模块的方法。
比较推荐的模块定义方法
1 | |
引用示例代码
1 | |
Python 相关
生成 requirements.txt 文件
方法一
1 | |
pip freeze命令输出的格式和 requirements.txt 文件内容格式完全一样,因此我们可以将 pip freeze 的内容输出到文件 requirements.txt 中。在其他机器上可以根据导出的 requirements.txt 进行包安装。
方法二
1 | |
生成指定目录下的依赖类库