现代 C++ 基础
Basics Review
Array Type
- Multidimensional array 多维数组
- 除了第一维其它维必须明确指出大小(explicit size)
- 不可以全部 decay
- Dynamic allocation
mallocin C andnew/new []in C++new和malloc返回都是指针- 释放
Function
函数返回类型不能是函数或者数组(但是可以是它们的引用)
- 不应该返回局部变量的指针或者引用(超出了局部变量生命周期的范围)
- e.g.
int& Test() { int a = 1; return &a;}
- e.g.
- 声明为
static的局部变量具有全局性
- 不应该返回局部变量的指针或者引用(超出了局部变量生命周期的范围)
Function pointers 函数指针
void(*)(int)clockwise/spiral rule
Type alias 用 C++ 11 中的
using1
2
3using MyFuncType1 = int(*)(float);
using MyFuncType2 = int(*)(int);
using MyFuncType3 = int(*)(MyFuncType1);C 语言中可以用
typedef,但是没有using强大
Attribute
[[attribute]]C++ 11,[[attribute("reason")]]C++ 20[[deprecated]]和[[deprecated("reason")]]C++ 14[[noreturn]]C++ 11[[maybe_unused]]C++ 17
e.g.
1 | |
warning: 放弃具有 [[nodiscard]] 属性函数的返回值
Enumeration
一个被限制取值的类
- 比较像使用全局变量
- 同时进行整形运算也没有安全检查
- C++ 11 引入了 scoped enumeration 提高安全性
e.g.
1 | |
- 可以使用
std::underlying_type<Day>::type或者std::underlying_type_t<Day>C++ 14 转成整数类型- C++ 23 中也可以使用
std::to_underlying<Day>(day)
- C++ 23 中也可以使用
- 可以使用
Day day{1};初始化 C++ 17,但是不能直接赋值Day day = 1;或day = 1; - 可以使用位操作符
Expression
- 运算符和表达式三个重要概念
- Precedence 优先级
- Associativity 结合性
- Order 顺序
- From the view of compiler, an expression is in fact a tree, determined by associativity and precedence. e.g.
9 / 3 / 2 + 2 * 3- Precedence is used to split terms first.
- Associativity determines how the tree will grow.
- Then, it’s order of expression evaluation that computes the whole tree. 但是顺序是不确定的
f1() + f2() + f3(),f1(),f1(),f1()哪一个先被 evaluated 是不确定的
- There are some rules
- For
&&and||, since they have short-circuit property, the first part will be fully evaluated. - For a function call, all parameters (including
afor e.g.a.Func()ora->Func()) are fully evaluated before entering the function. - 三目运算
- 逗号表达式
- C++ 17
- Parameters in function are evaluated indeterminately, i.e. every sub-tree represented by te parameter is fully evaluated in a non-overlap way 不会以交叠的形式 evaluated
- 运算符重载,和 build-in 运算符的 evaluated 顺序一致,而不是被当作普通函数
- More useful examples: chained call
- For
1 | |
class
Ctor & Dtor
- 拷贝构造函数
- 赋值构造函数
- The recommended way is member initializer list:
member1{...}, member2{...}, ... {/* function body */}{}is used since C++ 11
- 默认构造函数建议使用
Class() = default; - 如果成员变量有默认值,就不建议使用上面的构造函数的形式,而是直接用默认值初始化
Initialization of Object
- Since C++ 11, Uniform Initialization is introduced
- 所有的初始化都可以用
{} - 相比于
()更安全 Narrowing Conversion 缩窄变换检查- the converted type cannot represent all values
uint32_t类型用uint16_t初始化,编译器会报错
- the facilitates type safety
- the converted type cannot represent all values
- 所有的初始化都可以用
- Value initialization: No parameter for initialization
T a(),T a{},new T{},new T() - Direct initialization:
T a(x, y, ...),T(x, y, ...),new T(x, y, ...),T a{x, y, ...} - Copy initialization:
T a = xx;,T a[] = { xx, ...};- Ctors that use
explicitcannot use this way - Before C++ 17, this also requires available copy ctor.
- Ctors that use
1 | |
- List initialization
- Aggregate initialization
Member Functions
- 所有的成员函数都隐式有一个
this指针 - 如果期望函数不能更改成员变量,可以使用
const关键字 makethisto beconst - 静态成员函数
- 没有
this指针
- 没有
Access Control
private、protected、public,默认是privateprotected用在继承中- 友元
Inheritance
- 子类 / 派生类、父类 / 基类
- 子类 / 派生类可以访问父类中所有
public和protected成员 - 继承和组合
- 派生类可以隐式的转化成基类
Slicing Problem
1 | |
- There exists implicit conversion in
student1Ref = student2so actually it callsPerson::operator=(const Person&) - Can decorating
operator=withvirtualhelpPerson::operator=needsconst Person&butStudent::operator=acceptsconst Student&参数都不一样,虚函数都不生效
- This is called “slicing” because such operation will only affect the base slice but not the initial object as whole 只影响了一小片
- Polymorphic base class should hide their copy & move functions if it has data member, otherwise deleting them 对于具有多态属性的基类,应该隐藏它们的拷贝和移动函数
- Make copy & move functions
protectedso derived class can call them
Multiple Inheritance
1 | |
- Dreaded diamond
- C++ introduces virtual inheritance
- All virtual bases will be merged and seen as the same
1 | |
- That is, you define many ABCs, which tries to reduce data members and non-pure-virtual member functions as much as you can 定义很多抽象类,尽可能减少成员变量和非纯虚函数的数量,最好是没有
- They usually denote “-able” functionality 这样展现出来的就是就有某种能力
Polymorphism 多态
- you can use the base class to load the derived object and call its own methods 使用基类的指针 / 引用,承载派生类的对象,从而调用派生类的方法
- virtual pointer and virtual table
- Every object whose class has a virtual method will have a virtual pointer, which points to virtual table of its class 每个类中都有一个指向虚表的指针,虚表内容就是声明为
virtual函数的地址 - In C++ 11, it’s recommended to use
override子类没有override编译器会报错 finalIt means override, and the derived class cannot override again 继承链中的最后一个节点class A final {...};让类不能被继承- 去虚化,编译优化
abstract class抽象类- 抽象类不能被实例化
- 可以是使用抽象类的指针,指向的都是派生类的对象
- C++ 通过纯虚函数实现抽象类
virtual void PrintInfo() const = 0; - 派生类继承自抽象类必须实现纯虚函数,否则仍然是抽象类
- Don’t call any virtual function and any function that calls virtual function in ctor & dtor 在构造函数和析构函数中不要调用任何虚函数,也不要掉调用任何可能调用虚函数的函数
- You should usually make dtor of base class
virtual通常将析构函数声明为虚函数- deleting
Base*that cast fromDerived*will lead to correct dtor 派生类指针赋给基类,当调用delete时,如果不基类不是虚析构函数,就会调用基类的析构函数
- deleting
- 构造函数不能是纯虚函数
Some Covert Facts in Inheritance
override不止表示复写虚函数的含义,对于非虚函数的复写也叫“override”privateinheritance usually denotes the relation of has-a- 虚函数的返回类型可以有些许改变:you can use
Base*to both acceptBase*andDerived*复写虚函数的返回值可以是指向基类的指针,也可以是指向派生类的指针- 智能指针不能有“协变”
- 当虚方法有默认参数的时候,用什么类型的指针调用时,就会返回该类型内的默认值
- 默认的参数在编译期间被识别,虚表是在运行时跳转的
e.g.
1 | |
- 可以更改虚方法的访问属性(但是不建议)
struct
- 和
class基本上一样,除了struct默认的访问控制是public- 不应该有成员函数,最多有 ctor、dtor 和运算符重载
- With these constraints (except for ctor),
structwill be an aggregate, which can use aggregate initialization- Since C++ 20, aggregate can also use designated initialization 指定初始化
e.g.
1 | |
Function Overloading 函数重载
- C++ 中就是相同的函数名不同的参数
- C 中是禁止的
- This is done by compilers using a technique called name mangling
- Operator Overloading 运算符重载
+,-,*,/,%,|,&,^,<<,>>:推荐使用在全局函数中+=,-=,*=,/=,|=,&=,^=,<<=,>>=:必须是成员函数 since the first operand must be a “named” object; return reference (i.e.*this)- Prefix
++& Prefix--:必须是成员函数 return*this - Postfix
++& Postfix--have an unused parameter int, which is used to distinguish the prefix and postfix *,->:usually used in e.g. some wrapper of pointers&&,||:short-circuit 特性会失效<=>:三路比较运算符()[]- Since C++ 23, you can use multidimensional subscript in
operator[]
- Since C++ 23, you can use multidimensional subscript in
Lambda Expression
- 本质上是一个匿名的
struct,重载了operator() const方法 - Basic format:
auto func = [captures](params) -> ReturnType {function body;};- Captures are actually members of the
struct - ReturnType, params and function are for
operator() - Every lambda expression has its unique type
- 不传任何参数
()可以省略掉
- Captures are actually members of the
- 建议将 Lambda 表达式中的捕获的东西明确写出来
- static 和 global 变量是不需要被捕获的
- 捕获
this指针thisby reference, since only copy pointer*thisreally copy all members- 包括私有成员也可以捕获
- You may add specifiers after
()mutable: since C++ 17, removeconstinoperator()static: since C++ 23, same asstatic operator()constexpr、consteval、noexcept
1 | |
- It’s also legal to add attributes between
[]and() - 函数也可以写成 Lambda 表达式的形式
auto Foo(params) -> ReturnType {function body;}
Code Block With Initializer
1 | |
it会泄露出去,下面如果继续判断会再定义迭代器类型的变量- Since C++ 17, you mey code like
1 | |
- Since C++ 20, range-based for loop can also add an additional initializer, e.g.
for (auto vec = GetVec(); auto& m : vec); - Since C++ 23, type alias declaration can also be initializer, e.g.
if (using T = xx; ...)
Template
- Since C++ 17, CATD(class template argument deduction) is introduced, meaning that the argument of ctor can deduce the template parameter of class. e.g.
std::vector v{1, 2, 3, 4} - Lambda expression can also use template
Container
std::size_t: the type ofsizeof()意味着对象的大小不能超过std::size_t所表示的范围- 也意味着数组的大小不能超过
std::size_t所表示的范围 - 容器的大小也不能超过
std::size_t
- 也意味着数组的大小不能超过
std::ptrdiff_t:两个指针相减得到的类型
Iterators
- Input/Output iterator
- For output
*it = val,it++,++it, ‘it1 = it2’ - For input
==,!=,->
- For output
- Forward iterator: e.g. linked list
- Bidirectional iterator:
--it,it--e.g. double linked list, map - Random access iterator:
+,-,+=,-=,[],<,>,<=,>=,!=e.g. deque - Contiguous iterator (since C++ 17): 保证地址空间是连续的
- IMPORTANT: Iterator are as unsafe as pointers 线程不安全的
- All containers can get their iterators by:
.begin(),.end().cbegin(),cend()read-only access
- 双向链表等还提供了倒序的遍历迭代器
.rbegin(),.rend(),.crbegin(),crend()
- 还可以使用全局的方法得到迭代器
std::begin(vec),std::end(vec)- C++ 20 建议使用
std::ranges::begin - 只有类似
int arr[5]传入到std::begin()或std::end()中才有效,指针传入进来是无效的
- There are also general methods of iterator operations, defined in
<iterator>std::advance(InputIt& it, n):it += nstd::next(InputIt it, n = 1):return it + nstd::prev(InputIt it, n = 1):return it - nstd::distance(InputIt it1, InputIt it2):return it2 - it1不同的容器时间复杂度不一样
Iterator traits(显著的特点,特征)
- Iterators provide some types to show their information:
value_type: The type of elements referred todifference_type: The type that can be used to represent the distance between elements (usuallyptrdiff_t) 迭代器之间的距离所表示的类型,一般就是ptrdiff_titerator_category: e.g.input_iterator_tag,continuous_iterator_tagpointer&reference: only available in container iterators 只有在容器中才会有的特性- 可以使用
std::iterator_traits<IteratorType>::xxx获取
- 可以使用
Stream iterator
std::istream_iterator<T>&std:ostream_iterator<T>- The default constructed
istream_iteratorisend()默认的构造函数表示终止的迭代器
Iterator adaptor
有两种类型的迭代器适配器
- One is created from iterators to preform different utilities:
- E.g. reversed iterators 反向迭代器,++ 的本质上是 –,所以可以用
begin()初始化,即std:::reverse_iterator r{p.begin() } - You can get the underlying iterator by
.base(), which actually returns the iterator that points to the elements after the referred one 调用.base()实际上是指向当前指向位置的下一个元素rbegin().base() == end()
- E.g. reversed iterators 反向迭代器,++ 的本质上是 –,所以可以用
- Another is created from containers to work more than “iterate”
std::back_insert_iterator{container}:*it = valwill callpush_back(val)to insertstd:front_insert_iterator{container}: callpush_front(val)to insertstd::insert_iterator{container, pos}: callinsert(pos, val)to insert
- Notice that inserting/assigning a range directly is usually better than inserting one by one for
vectorordeque
Sequential Container
Array
- E.g.
int a[5]will decay toint*when passing to function, and the size information is dropped 以参数的方式传递到函数中会退化成指针,并且大小也被舍弃了 std::array<T, size>the same asT[size]. It always preserves size, can copy from another array, and can do more things like bound check- It’s allocated on stack
- But if you
new std::array, then it;s still allocated on heap
- But if you
- 特殊的构造函数需要额外的
{}e.g.struct S {int i; int j;}初始化时是std::array<S, 2> arr{{{1, 2}, {3, 4}}}- 第一个
{}是array本身初始化的{} - 第二个
{}是数组初始化的{}
- 第一个
- For member accessing 成员访问
operator[]at()will check the boundfront(),back(): get the first/last element of vector 首先要保证非空- If you want to get the raw pointer of array content, you can use
.data()
- Additional methods
.swap()operator=,operator<=>三路比较运算符.fill()将整个数组填充为某个特定值std::to_array(C-style array)
- Size operations
.size(): returnsize_tempty().max_size(): get maximum possible size in this system(usually useless)
vector
- 动态数组
- 支持随机访问,占据连续空间
- When inserting and removing elements at the end (i.e. pushing/poping back), the complexity is amortized(均摊)
- If not at end, it’ll be
- 在 cache 上的效果非常不错,对 cache 利用率非常显著
- 实现思路
- 准备一部分空间,这样在 pushing 或者 poping 的时候时间复杂度才是
- 当容量不够的时候在重新分配(reallocation),重分配的均摊复杂度也要求是
- The element number is called size; total space is called capacity
- 重分配的策略
- The easiest strategy is increasing space linearly
- E.g. 0 -> 4 -> 8 -> 12 -> 16 -> …
- Every
operations will trigger reallocation an copy elements - So, the amortized complexity is
- Considering that
is an constant, this is still
- So, the amortized complexity is
- So, what about exponentially(指数)?
- E.g. 1 -> 2 -> 4 -> 8 -> 16 -> 32 -> …
- Every
operations will trigger reallocation an copy elements - So, the amortized complexity is
- So, the amortized complexity is
- Finally, why is the exponent 2?
- 可以证明任何大于 1 的指数最后的均摊复杂度都是
- This is a trade-off between space and time 空间和时间的权衡
- In MS(微软), it’s 1.5
- 可以证明任何大于 1 的指数最后的均摊复杂度都是
- The easiest strategy is increasing space linearly
- vector 不会自动的进行缩容(shrink),但是会暴露出接口手动缩容
- Insert 是从后向前的(move backwards)
- Removal is similar, but move forwards from the end of deletion to the deletion point, and finally destruct the last several elements
std::initializer_list- For member accessing (same as array)
- operator[]
,at(): accessing by index;at()will check th bound, i.e. if the index is greater than size,std::out_of_range` will be thrown front(),back(): get the first/last element of vector- If you want to get the raw pointer of array content, you can use
.data()
- operator[]
- For capacity operations (i.e. adjust memory)
.capacity(): get capacity (returnsize_t).reserve(n): 直接分配n大小的内存,如果比当前 capacity 小就什么都不做,size 是不会改变的- 作用是前提知道需要分配的数量,一次性分配,就不需要有扩容的操作了
.shrink_to_fit: request to shrink the capacity so thatcapacity == size
- For size operations
.size().empty().resize(n, obj = Object{}).clear(): remove all things; size will be 0 after this
.push_back(obj).emplace_back(params): insert an element constructed by params at the end 就地根据params构造元素- Since C++ 17, it returns reference of inserted element (before it’s
void)
- Since C++ 17, it returns reference of inserted element (before it’s
.pop_back().insert(const_iterator pos, xxx).erase(const_iterator pos),.erase(const_iterator first, const_iterator last): erase a single element/elements from[first, last)- insert/erase will return next valid iterator of inserted/erase elements
- Interact with another vector
.assign.swap(vec)
- Since C++ 23, ranges-related methods are added
.assign_range(Range)insert_range(const_iterator pos, Range)append_range(Range)
- 准备一部分空间,这样在 pushing 或者 poping 的时候时间复杂度才是
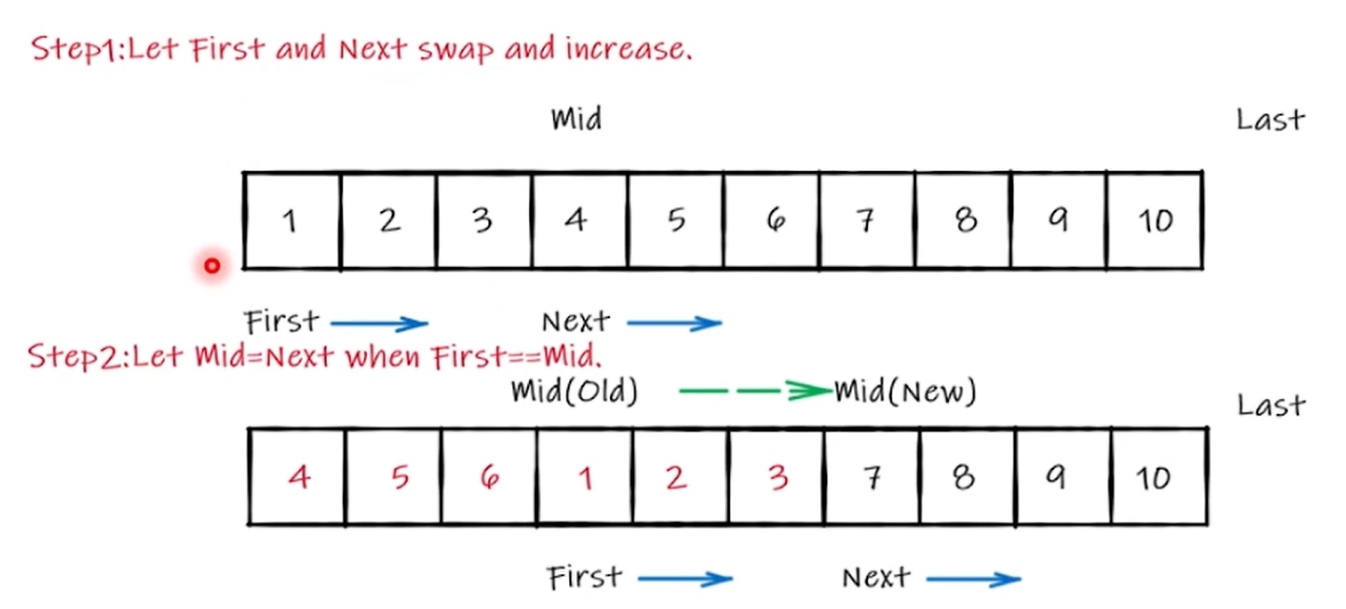
Iterator Invalidation
迭代器就是指针的包装,但是指针是不安全的
导致不安全的情况
- reallocation 重分配,造成原来保存的指针悬垂
- Insertion & removal 插入和删除
For vector
If the capacity changes, all iterators are invalid
1
2
3
4
5
6
7
8
9#include<vector>
int main()
{
std::vector{1, 2, 3, 4};
auto it = v.begin();
v.reserve(10086); // 会导致上一行的 `it` 失效
it = v.begin(); // 必须进行重新获取
}If the capacity doesn’t change, but some elements are moved, iterators after the changed points are invalid
Span
- 视图 View means that it doesn’t actually hold the data; it observes the data
- Span is a view for contiguous memory (e.g. vector, array, string, C-style array initializer list, etc.)
- 可以像 array 一样操控 span
.first(N)/.last(N).subspan(beginPos(, size))- span is just a pointer with a size
Dequeue Double-Ended Queue 双端队列
- 最主要的特点就是
on insertion & removal of elements at the front or the back - Random access
- Other properties are just like vector
push_frontemplace_frontpop_frontprepend_rangeC++ 23
- Circular queue
- When enqueue, tail moves forward
- When dequeue, head moves forward
- If
tail == headi.e. the queue is full, overwrite the element at head, both tail and head move forward
- Dequeue 相当于动态的循环队列,当队列满的时候需要进行扩容
- 扩容是做到均摊复杂度是
- 可以做到随机访问的原理是 e.g.
deque[i]is justvec[(head + i) % size]
- 扩容是做到均摊复杂度是
- 实现方式
- 降低拷贝的代价
- 通常的实现方式是使用动态循环队列(called map),里面的元素是指针
- 指针指向一个 block,block 中存储对象
- block 的大小是固定的
- Dequeue 中的数据结构
- The map and its size
- The block size
- The global offset of the first element
off- We can use
off / block_sizeto know the position of head
- We can use
- Element numbers
- 重新分配的时候只需要拷贝指针
- Map reallocation in dequeue
- 假设新加的 block 的大小是
count - 需要使得循环队列仍然是连续的
- First, copy all elements from
vec[head, vecEnd]tonewVec[head, currEnd] - Then, if
head <= count, copy[0, head)to[currEnd, ...) - Else, copy after
currEndas mush as possible, and the rest is arranged to thenewVecBegin - Finally, set all the rest to
nullptr
- First, copy all elements from
- 假设新加的 block 的大小是
- Dequeue iterator invalidation
- All iterators are seen as invalid after insertion 插入之后所有的迭代器都是失效的,还包括
resizeshrink_to_fitclear
- All iterators are seen as invalid after insertion 插入之后所有的迭代器都是失效的,还包括
List
- Double linked list
- Properties
insertion and removal splice 融合另一个 list 的一部分元素 - 不支持随机访问
- 每个节点都已一个数据
T data、prev、next,并且第一个节点的prev指向nullptr,最后一个节点的next指向nullptr - 微软用循环 list 实现的
- 引入了哨兵节点 sentinel node,是
prev指针的前一个节点,next指针的后一个节点 - 不需要特判 nullptr`
- 引入了哨兵节点 sentinel node,是
- There are two methods to move nodes from another list
- 和
insert(pos, it1, it2)有区别,insert只是拷贝,没有清除操作 .merge(list2)/.merge(list2, cmp),通常用在已排序的 list 中.splice(pos, list2, ...)(): insert the totallist2to pos(it2): insertit2topos(and remove it fromlist2)(first, last): insert[first, last)topos(abd remove them fromlist2)
- 和
Froward list
- Single linked list
- Forward list 的目的是为了减少存储空间,所以不提供
.size()函数 - 只存储头部节点
Container adaptors
- 容器适配器是对已经存在的容器进行包装,通常情况下不提供迭代器
Stack
- Stack is a LIFO data structure
- The provide container show have
push_back,emplace_back,pop_back, so vector, deque and list are all OK - APIs
.pop().push(val),.emplace(params).push_range(params)C++ 23.top().empty(),.size().swap(s2)operator=operator<=>
Queue
- Queue is a FIFO data structure
.front().end()
Priority queue
- It’s defined in
<queue> - It’s in fact max heap
- 插入或者弹出元素的时间复杂度是
- 建堆的时间复杂度是
- Percolation is the core algorithm
- 插入的时候进行上滤 percolate up
- 删除的时候进行下滤 percolate down
- 插入或者弹出元素的时间复杂度是
Flat containers
- The only defect of map/unordered_map/… is that they’re really cache-unfriendly
- Flat containers 对缓存利用率更高
- The functionality is same as set/map
- But it’s in fact an ordered “vector”
- 没有冗余的数据,对 cache 更友好
- 本质上是两个 “vector”
- The whole definition is
std::flat_map<Key, Value, Compare = std::less<Key>, ContainerForKey = std::vector<Key>, ContainerForValue = std::vector<Value>> - 也可以使用 deque 作为容器
- The complexity
- For lookup,
二分查找 - For insertion/removal,
- For
iterator++,
- For lookup,
Associative containers
- They’re called associative because they associate key with value
- The value can also be omitted
- There exist ordered one and unordered one
- 有序的需要比较函数 less than
- BBST (balanced binary search tree) 查找、插入、删除的时间复杂度都是
- RB tree
- AVL
- BBST (balanced binary search tree) 查找、插入、删除的时间复杂度都是
- 无序的需要提供哈希函数和判断是否相等的函数
- 查找、插入、删除的时间复杂度都是
- 查找、插入、删除的时间复杂度都是
- 有序的需要比较函数 less than
Map
- The key is unique; a single key cannot be mapped to multiple values
std::map<Key, Value, CMPForKey = std::less<Key>>- 默认是小于号
CMPForKeyshould be able to acceptconst key
- For member accessing
operator[],at()- Bidirectional iterators
- Notice that the worst complexity of
++/--is - 对 BBST 进行中序遍历就能得到有序的序列
.begin()is just the leftmost node and.rbegin()is just the rightmost node
- Notice that the worst complexity of
- Note
operator[]will insert a default-constructed value if the key doesn’t exits- 如果 key 不存在并且默认构造的值也不是真正需要的,用
insert_xxx效率更高 const map不能用operator[]- 如果 value 是不能被默认构造的(例如没有默认构造函数)也是不能用
operator[]
- 如果 key 不存在并且默认构造的值也不是真正需要的,用
- Key-value pair is stored in RB tree, so iterator also points to the pair
- You can use structured binding to facilitate iteration
1 | |
APIs
.lower_bound(key): finditthatprev(it)->key < key <= it->key- Use key as a lower bound to make
[it, end) >= key
- Use key as a lower bound to make
.lower_bound(key): finditthatprev(it)->key <= key < it->key- Use key as a lower bound to make
[begin, it) <= key
- Use key as a lower bound to make
.equal_range(key): finditpair with the same key askeyin rangeInsertion
因为键是唯一的,插入的时候如果 key 存在会失败;无论失败成功都返回
pair<iterator, bool>- If succeed,
iteratorrefers to inserted element andboolistrue - If fail,
iteratorrefers to the element with the same key andboolis false`
- If succeed,
插入失败会有多个处理方式
- Leave it unchanged
.insert({key, value}).emplace(params)
- Overwrite it (C++ 17)
.insert_or_assign(key, value): returnpair<iterator, bool>
- Leave it unchanged and even not construct the inserted value (C++ 17)
.try_emplace(key, params): same asemplace, except that the params are used to construct value, andemplaceis not forbidden to construct the pair in failure 构造 value 非常昂贵的时候使用
- Leave it unchanged
You can also provide a hint iterator for insertion
hint iterator 在被插入元素后面的时候会有效率提升,在前面的话会使效率降低
Hint is often used in idiom blow
1
2
3
4
5
6
7
8auto pLoc = someMap.lower_bound(someKey);
if (pLoc != someMap.end() && !(someMap.Key_comp()(someKey, pLoc->first)))
return pLoc->second;
else {
auto newValue = expensiveCalculation();
someMap.insert(pLoc, make_pair(someKey, new Value));
return newValue;
}
Erasure
.erase(...)(key)(iterator pos)(iterator first, iterator last)
.extract(key),extract(iterator pos): extract out the node from the map.insert(node_type&&): insert the node to the map.merge(another map/multimap)
Structured binding
Structured binding is just
auto& [...]{xx}
{xx}can be(xx)or=xx
auto&can be anything
xxcan be a pair; it can also be
- An object with all public data members, which will be bound on them
- A C-style array or
std::array, which will be bound on elementsarr[i]- A tuple-like thing, which will be bound on every element
Note
pair and
std::arrayis also somewhat tuple-like thing and can use some tuple methods, e.g.std::getpair 和std::array也可以像 tuple 一样,访问的时候也可以使用访问 tuple 的方法结构化绑定时一个新的声明,不能绑定已经存在的变量,如果想绑定已存在的变量可以使用
std::tie(name, score) = pair结构化绑定的本质是匿名结构体,结构体中的变量是别名
2
3std::tuple<int, float> a{1, 1.0f };
const auto& [b, c] = a;
decltype(b) m = 0; // const int m = 0;Structured binding is usually more efficient than novice/careless programmers 建议使用结构化绑定
Tuple
std::tuple<int, float, double> t{1, 2.0f, 3.0};- It can only be accessed by an index that can be determined in compile time 下标访问的下标只能在编译时确定
std::get<0>(tuple)to get theint 1- C++ 14 可以使用类型获取相应的值,前提是类型不能重复 e.g.
std::get<int>(tuple)std::tuple_cat
Set
- Set is just a map without value
- The only difference with amp is that it doesn’t have
operator[]and.at() - The iterator points to only key instead of key-value pair
Multimap
- 把 key 的唯一性取消了
- 不能使用
operator[]和.at() - 相等的值的顺序取决于插入时的顺序
- 插入永远都是成功的
- Nodes of multimap and map can be exchanged 两个容器的节点是可以相互替换的
Multiset
- Except for only key and no value, same as multimap
- You can also exchange nodes of multiset and set
Unordered map
std::unordered_map<Key, Value, Hash = std::hash<key>, Equal = std::equal_to<Key>>- Many types have
std::hash<Type>, e.g.std::string,float, etc. - The hash value of different keys may be same, so we need
Equalto judge which key is wanted - 微软的实现在解决冲突的时候用双向链表,并且链接相邻的 Bucket 延申出来的双向链表,并添加一个哨兵节点
- 当插入数据太多的时候,每个 bucket 也会链接很多数据
- 这样会增加查找的复杂度
is called load factor 装载因子 - 装载因子过大时,需要对 bucket array 进行扩容
- Rehash 重哈希
- APIs
.bucket_count(): size of bucket array.load_factor():size() / bucket_count().max_load_factor(): when load factor exceeds this limit, refresh will happen.rehash(n): makebucket_count() = max(n, ceil(size() / max_load_factor()))and rehash.reserve(n).bucket(key): get the bucket index of the key.begin(index),.cbegin(index),.end(index),.cend(index): get the iterator of the bucket at index.bucket_size(index): get the size of bucket at index
- You can also extract nodes and insert them
Ranges
Using ranges is very like functional programming
There are three important components in ranges:
- Range: A type provides a begin iterator and end sentinel, so that it can be iterated over
- View: A range that can be moved in
, copied in (or cannot be copied) and destructed in - Range adaptor
Note
- Range 可以按照迭代器进行分类
- 计算是惰性计算
They’re all defined in
<range>; all views are defines asstd::ranges::xx_view, and all range adaptors are defined asstd::views::xx- 一般用别名来简化定义
namespace stdr = std::ranges和namespace stdv = std::views stdr::iota_view{lower, upper = INF},stdv::iota(lower, upper = INF): 和 python 中的range(a, b)类似
1
2
3
4
5
6for (const auto oddNum : stdv::iota(1, 10)
| stdv::filter([](int num) {return num % 2 == 1; })
| stdv::take(3))
{
std::cout << oddNum << '';
}- 一般用别名来简化定义
Writable
stdv::filter(Pred): drop the element if the predicate functionPredreturnsfalsestdv::take(x): take firstxelements (but not exceedend)stdv::take_while(Pred): take elements untilPredreturnfalse(orend)stdv::drop(x): drop firstxelementsstdv::drop_while(Pred): drop elements untilPredreturnsfalsestdv::reversestdv::keys: get the first element from a tuple-like thingstdv::valuesstdv::elements<i>: get theith element from a tuple-like thingstdv::stride(k): usekas stride to iterate- e.g.
stdv::iota(1, 0) | stdv::stride(2)gets{1, 3, 5, 7, 9}
- e.g.
stdv::join: flattens the ranges to a single range 需要用|连接stdv::join_with(xx): fill the interval withxx需要用|连接stdv::zip(r1, r2, ...): zip values from ranges to a tuplestdv::cartesian_product(r1, r2, ...): return a tuple of elements from the cartesian product of these rangesstdv::enumerate: returnstd::tuple<Integer, T&>; Integer is index whose tpe is diff type of iteratorstdv::slide(width): slide the range in a sliding window ofwidth- e.g.
std::vector v{1, 2, 3, 4, 5}; v | stdv::slide(3)gets{{1, 2, 3}, {2, 3, 4}, {3, 4, 5}}
- e.g.
stdv::adjacent<width>: same asstdv::slide(width)stdv::pairwise: i.e. stdv::adjacent<2>stdv::chunk(width): partition the range bywidthstdv::chunk_by(pred2): partition the range bypred2, i.e. a view sill stop whenpred2(*it, *next(it))returnfalsestdv::split(xx)stdv::lazy_split(xx)
Read-only
Either make the view const, i.e.
std::as_const; this will returnconst T&ortuple<const T&, ...>Or return value, i.e. transform-related, which will return
Tortuple<T, ...>stdv::zip_transform(TransformN, r1, r2, ...): return a view ofTransformN(ele1, ele2, ...)stdv::adjacent_transform<N>(TransformN): return a view ofTransformN(...), where...is the elements of the sliding windowsstdv::transform(Transform): transform element to another element1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16std::vector<int> v{1, 2, 3, 4, 5 };
int cnt = 0;
auto r = v | stdv::transform([&cnt](const int ele) {
std::cout << std::format("cnt={}, ele={}\n", cnt, ele);
cnt++;
return cnt + ele;
}) | stdv::take_while([](const int ele) {return ele < 10; });
for (const auto& i : r);
// output:
// cnt=0, ele=1
// cnt=1, ele=1
// cnt=2, ele=2
// cnt=3, ele=2
// cnt=4, ele=3
// cnt=5, ele=3
// cnt=6, ele=4++will trigger transform sincetake_whileneeds the transformed value to advance the iterator (i.e. byPred(*it))const auto& ele = *itwill trigger it again- That’s because the result doesn’t reference some existing elements, but generate from temporary; every time you need it, lazy evaluation generate it again 太 lazy 了
- Sometimes, you may want to convert a range to a e.g. container, which needs to eagerly evaluate all
stdr::to, e.g.stdr::to<std::vector>()
There are also some naïve range factories
stdv::single(obj): make a view that copies/moves an object, i.e. the view owns only a single elementstdv::empty<T>: create an empty viewstdv::repeat(r, k = INF): repeat a rangerforktimes, i.e. like a range[r, r, r, ...]stdv::istream<xxx>(stream): similar toistream_iterator; it caches valuestdr::subrange(first, last)
Generator
1 | |
When the function reaches yield, it will pause and return the number; when iterator moves forward, the function will resume and continue to execute until the next yield or real return
- Since C++ 23, generator is also supported by coroutine
- Coroutines cooperates with each other and yield their execution flow themselves 协程之间是相互配合的控制流
- By contrast, for threads, they usually compete with each other and are interrupted by OS to give other threads chances to execute 线程则是抢占式的
- Coroutines cooperates with each other and yield their execution flow themselves 协程之间是相互配合的控制流
- Generator is just the same; when you need the next value , you just yield your execution flow to the generator function; when the generator function completes its task, it will give back the right of execution
- Generator is also an
input_rangeand view; it providesbegin()andend()to iterate, and++the iterator will resume the function- NOTICE: Call
.begin()will start the coroutine
- NOTICE: Call
e.g.
1 | |
- Some notes
- One generator can only be used once 只能使用一次
- Generator has
operator= co_returncan be omitted- Saving contexts also needs memory, so an allocator can also be provided as the last template parameter
Function 函数
Pointer to member functions
- Member functions can be static or non-static
- Static ones are just normal functions with some
Class::, their pointers are same as normal ones - Non-static ones are always bound to some specific objects, i.e. there is a
thispointer as a parameter
- Static ones are just normal functions with some
e.g.
1 | |
- Define a pointer to member function is
Ret (Class::*)(params) std::invokedefine in<functional>since C++ 17- Since C++ 23,
std::invoke_r<Result>is provided
Callable parameter
Function as parameter
- 函数指针也可以实现将函数视为参数来传递,但是有两个问题
- 有时候函数指针的参数类型有严格的限制,例如
intcan be converted todouble,func(double)is also acceptable - In C++, usually what you need is just “something callable”, i.e. a functor is allowed 有时候只是想传入一个可调用的类型
- 有时候函数指针的参数类型有严格的限制,例如
- 有两种方式解决
- Use a template parameter
<algorithm>常用的方法采用模板参数接受可调用的参数 - Use a
std::functiondefined in<functional>std::function<RetType(Args...)>can adopt almost all callable that have the return type convertible toRetTypeand acceptArgs- The member function even preserves polymorphism
- After getting the
std::function, you can just useoperator()to call it - Even more powerful, you can bind some parameters to get new functors
- E.g. you can use
std::bind(any_callable, params)to get astd::functionstd::bind已经没有用了,完全可以用 Lambda 表达式绑定
- E.g. you can use
- There are two defects
- Performance: It roughly causes 10% - 20% performance loss compared with direct function call
- 有可能会用
new/delete自定义ctor/dtor - 解决方式是使用 SOO(small object optimization),在栈上准备一块小的 buffer 用于分配函数空间
- 如果绑定的 Lambda 表达是太大可以使用
auto lambda = xx;,然后再通过std::ref(lambda)传给std::function的构造函数(但是要注意声明周期),但是不可以使用std::ref(&&xx)(){...},lambda 表达式会立马失效
- 有可能会用
- The second defect of
std::functionis that it cannot really accept all functors 并不是支持所有的可调用类型- When the functor is not copiable (e.g. move-only, like
std::unique_ptr) 仿函数不能拷贝的就不能接受- Thus, since C++ 23,
std::move_only_functionis introduced
- Thus, since C++ 23,
- When the functor is not copiable (e.g. move-only, like
- Performance: It roughly causes 10% - 20% performance loss compared with direct function call
- Reference wrapper
std::(c)ref()in fact createstd::reference_wrapper<(const) T>, which can be seen as an instantiated reference- 例如容器中不可能存储引用类型的,如果想储存引用类型可以使用
std::vector<std::reference_wrapper<T>> - It’s in fact a wrapper of pointer, but it cannot be null, just like reference
- Different from reference, it can be bound to another object by
operator=, just like pointer 引用是不可以换绑的,但是std::ref()可以
- 例如容器中不可能存储引用类型的,如果想储存引用类型可以使用
- It’s also used to denote “it should be a reference” explicitly in some methods in standard library, e.g.
std::bind_backorstd::bind_front
- Use a template parameter
- There are also some predefined template functors in
<functional>- Arithmetic functors:
plus,minus,multiplies,divides,modulus,negate - Comparison functors:
equal_to,not_equal_to,greater,less,greater_equal,less_equal,compare_three_way - Logical functors:
logical_and,logical_or,logical_not - Bitwise functors:
bit_and,bit_or,bit_xor,bit_not - These
Functor<T>all haveauto operator()(const T&, const T&) const
- Arithmetic functors:
Lambda expression
- We call lambda expression without capture stateless lambda; otherwise stateful lambda
- 可以使用
decltype(...)去推断 lambda 表达式的类型 - 理论上可以使用推断出来的仿函数的类型进行声明,但是只有再 C++ 20 之后才是合法的
- E.g.
auto l = [](int a, int b) {return a + b;}; using T = decltype(l); T l2{}; - 只适用 stateless lambda
- E.g.
Algorithms
Algorithms’ Consist
- Iterator pairs 迭代器对,或者直接传入 ranges
- Predicate function / transform function 判别函数或者变换函数,通常情况下变换都是
const&,或者对于比较小的类型传入拷贝 - 大部分算法都返回一个范围迭代器
- 从来都不会改变序列的大小
- Callables of algorithm are of value type instead of reference type 判别函数或者变换函数都是传递值类型,不是引用类型
Search
- 两种搜索算法
- Linear search
- Find single value
std::findstd::find_if
- Find one of values in a range
std::find_first_of
- Find a sub-sequence in a sequence (Pattern matching)
std::searchstd::find_end
- Others
std::adjacent_find(begin, end[, Pred2]): 相邻元素相等的位置std::search_n(begin, end, count, value, [, Pred2])
- Find single value
- Binary search, which is applied on sorted sequence
std::binary_search: return bool, denoting whethervalueexists in[begin, end)std::lower_bound: returnitso thatvalueis the lower bound of[it, end)std::upper_bound: returnitso thatvalueis the lower upper of[begin, end)std::equal_range: return an iterator pair(it1, it2)so thatvalueis equal to[it1, it2)
- Linear search
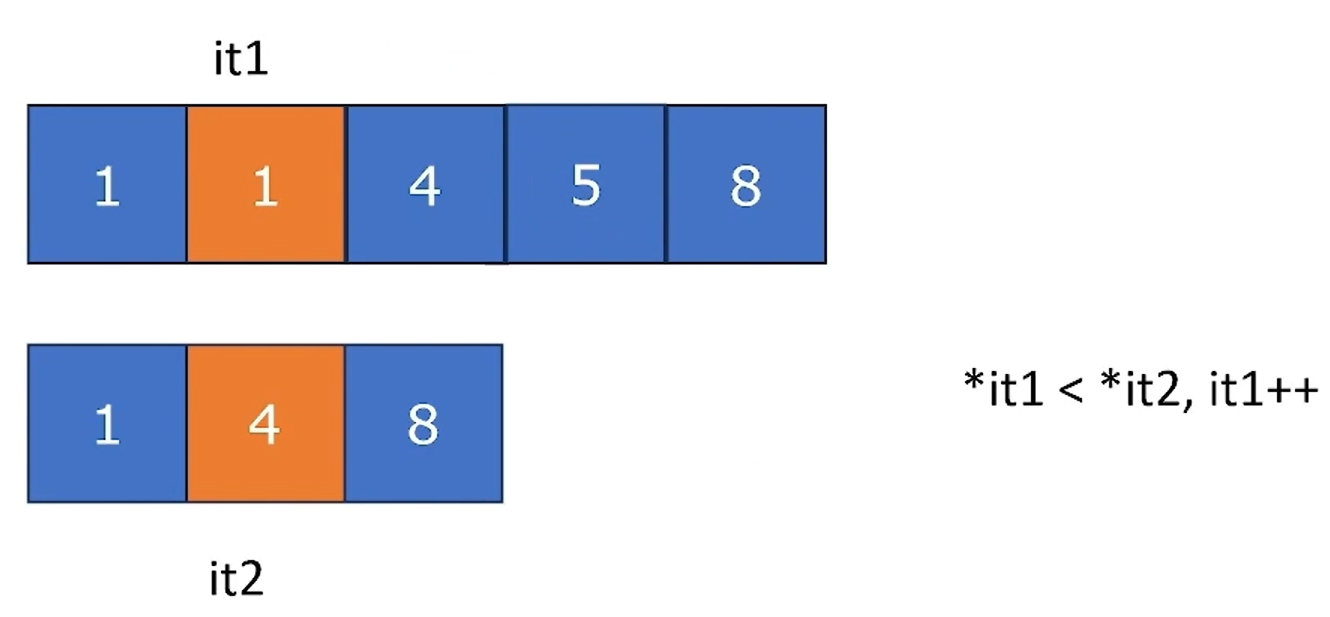
Comparison
std::equal(begin1, end1, ..., [, Pred2]): return a boolstd::lexicographical_compare(begin1, end1, begin2, end2[, Pred2]): return bool; Pred2acts asoperator<>`- Compare until
ele1 < ele2 || ele2 < ele1
- Compare until
std::lexicographical_compare_three_way(begin1, end1, begin2, end2[, Pred2]): return an ordering;Pred2acts asoperator<=>std::mismatch(begin1, end1, ...[, Pred2]): return an iterator pair(it1, it2)denoting the first occurrence of mismatching- These algorithms are all
Counting
std::all_of/any_of/none_of(begin, end, Pred)std::count(begin, end, value)std::count_if(begin, end, Pred)- These algorithms are all
Generating and Transforming
std::fill(begin, end, value)std::fill_n(begin, count, value)std::generate(begin, end, Gen): for each element in[begin, end),ele = Gen()std::for_each(begin, end, Transform): for each element in[begin, end), callTransform(ele)std::transform: There are unary/binary transforms(begin, end, dstBegin, Transform): unary 一元(begin, end, begin2, dstBeing, Transform): binary, the transformation isTransform(*it1, *it2)
Modifying
std::remove(begin, end, value)/std::remove_if(begin, end, Pred): return the iterator so that[begin, it)has no element that is equal tovalueor makePredreturntrue- 不会真的擦除迭代器
- Since C++ 20, they’re integrated as methods
std::erase/std::erase_if
std::unique(begin, end[, Pred2]): return the iterator so that[begin, it)has not adjacent equal element;Pred2acts asoperator==使得在[begin, it)区间内没有相邻且相等的元素- These algorithms are all
, by the technique of dual pointers 算法用双指针实现 - 定义两个指针
before和after - 两个指针一开始都指向
begin - 先前进
after - 判断
*before == *after;相等只前进after,不相等则前进before,并将after指向的值和before交换,前进after - 直到
after == end - 需要考虑
begin == end和整个序列就是 unique 的情况
- 定义两个指针
std::replace(begin, end, oldValue, newValue)/std::replace_if(begin, end, Pred, newValue)std::swap(x, y)std::iter_swap(it1, it2)std::swap_range(begin1, end1, begin2)std::reverse(begin, end)std::rotate(begin, mid, end): left rotate[begin, mid)- 2, 3, 4, 4, 5 -> 4, 5, 2, 3, 4 相当于左移
- Rotate is also
- brute-force method: swap each element ot its position (just like bubble sort). This will be
一个一个的交换,需要两层循环 - 可以考虑将第一个元素拿出来,再确定序列中哪一个元素会再下一步出现在第一个位置,然后进行替换,以此类推完成旋转
- 但是这种方式对 cache 不友好
- swap all groups together
- The complexity is
- The complexity is
- reverse
- In fact, reverse is the basis of many algorithms
[begin, mid - 1]``[mid, end - 1]- Reverse two sub-sequences, get
[mid - 1, being]``[end - 1, mid] - Reverse the total sequence, get
[mid, end - 1]``[begin, mid - 1] - The complexity is
- brute-force method: swap each element ot its position (just like bubble sort). This will be
std::shift_left/right(begin, end, n): the dropped elements are permanently dropped (invalid)
Copying
std::copy(begin1, end1, dstBegin)std::copy_if(begin1, end1, dstBegin[, Pred])std::copy_n(begin1, n, dstBegin)std::copy_backward(begin1, end1, dstBegin)
Partition and Sort
Partition
Partition denotes that a range is divide into two parts; assuming predicate function Pred, then there exists an iterator it (i.e. partition point 轴点) so that all elements in [begin, it) make Pred return true while [it, end) make Pred return false 左边的都小于轴点(使得 Pred 函数返回 true),右边的都大于轴点(使得Pred 函数返回false)
std::is_partitioned(begin, end, Pred)std::partition(begin, end, Pred)std::stable_partition(begin, end, Pred): each sub-partition preserves the original order 保证 partition 后的结果和原序列的顺序一致- 原序列
{0, 1, 9, 4, 5, 2, 7, 8},Pred为[](const int ele) {return ele % 2;}左边是奇数右边是偶数 std::partition:{7, 1, 9, 5, 4, 2, 0, 8}std::stable_partition:{1, 9, 5, 7, 0, 4, 2, 8}- Implementation:
- When the memory is enough (内存足够), prepare a buffer; move the
falserange to the buffer and move thetruerange to be consecutive (just like preformstd::remove_if(), with removed range saved in buffer). Then move the buffer elements back - When the memory is not enough (内存不够), divide the sequence into two halves and stable partition each half
- This will from
[true, false], [true, false]sequence 最终都会变成这样的序列 - Rotate the middle
[false, true]so that the final result is totally partitioned , to it’s overall
- This will from
- When the memory is enough (内存足够), prepare a buffer; move the
- 原序列
std::partition_point(begin, end, Pred): assume the range is a partition 前提是序列已经是 partition
Sort
std::is_sorted(begin, end[, Pred2])std::is_sorted_until(begin, end[, Pred2])std::sort(begin, end[, Pred2])std::stable_sort(begin, end[, Pred2])space complexity, time complexity - If space is insufficient,
time complexity
- Since
std::sortrequires the complexity exactly, quick sort is not enough 快排只是平均意义上的 ,最坏的情况是 - C++ 标准库广泛使用的排序算法是 Introspective Sort(IntroSort)
- It integrates insertion sort, heap sort and quick sort 结合了插入排序,堆排序和快排
- When the element number is low enough, insertion sort is used
- When the recursion is too deep, heap sort is used
- 避免快排的最坏情况
- 堆排序是稳定
- 堆排序速度不是很快,对 cache 也不是很友好
std::partial_sort(begin, mid, end)std::nth_element(begin, mid, end): rearrange[begin, end)so that*midis sorted (i.e. same as the*midin the full sorted range) and the whole range is partitioned by it 在排好序的中第 n 个位置的元素std::merge(begin1, end1, begin2, end2, dstBegin[, Pred2])std::inplace_merge(begin, mid, end)
Heap
std::is_heap(_until)(begin, end[, Pred2])std::make_heap(begin, end[, Pred2]): Floyd algorithmstd::push_heap(begin, end[, Pred2])std::pop_heap(begin, end[, Pred2])std::sort_heap(begin, end[, Pred2])
Set Operations
Set operations are used on sorted range, including set
std::includes(begin1, end1, begin2, end2[, Pred2]): check whether th second range is subset of the first range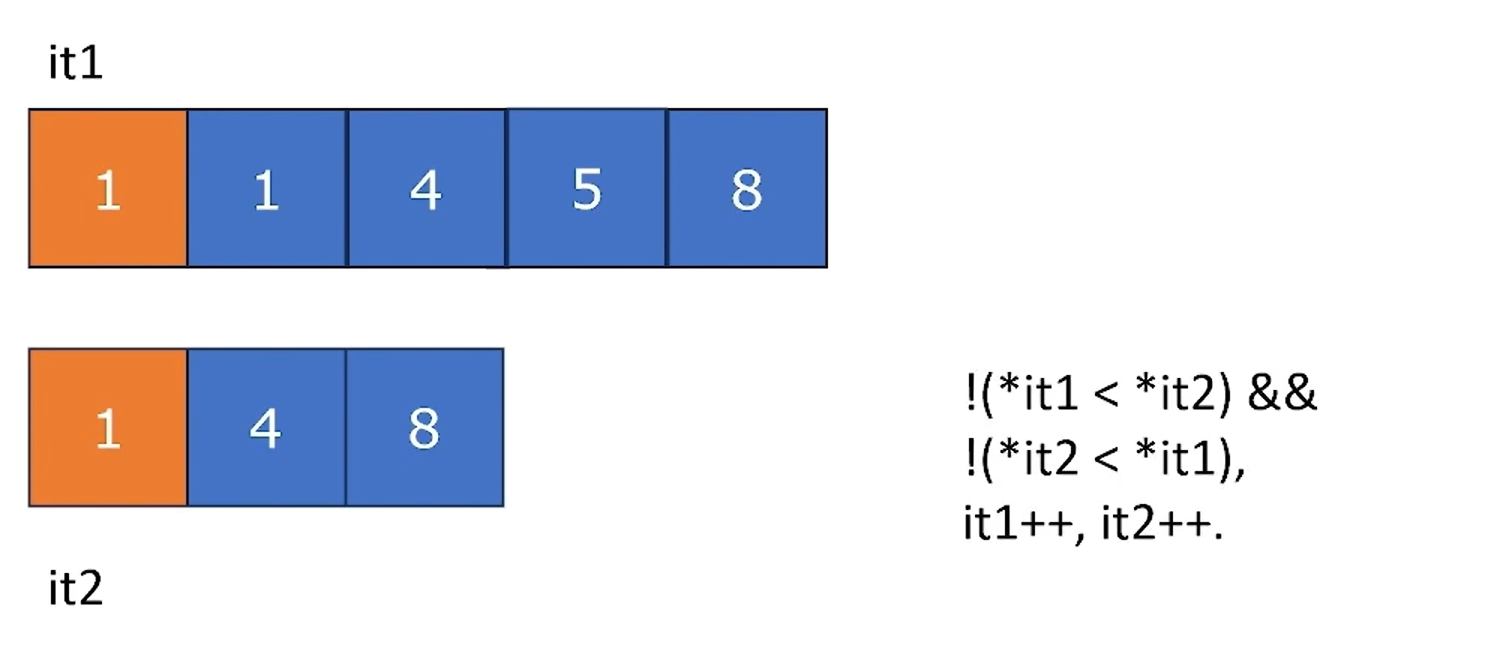
std::set_intersection(begin1, end1, begin2, end2, dstBegin[, Pred2]):std::set_union(begin1, end1, begin2, end2, dstBegin[, Pred2]):std::set_symmetric_difference(begin1, end1, begin2, end2, dstBegin[, Pred2]):std::set_difference(begin1, end1, begin2, end2, dstBegin[, Pred2]):
MinMax
std::min/max/minmax(a, b[, Pred2]): return (pair of) reference of the smaller/bigger elementstd::min_element/max_element/minmax_element(begin, end[, Pred2]): return the iterator of the minimum/maximum value in the rangestd::clamp(value, low, high)
Permutation
Permutation means that two sequence are unorderly equal
std::is_permutation(begin, end1, begin2[, Pred2])std::prev/next_permutation(begin, end[, Pred2]): return the sequence to the previous/next permutation
Numeric Algorithms
They are all
- For the most basic ones:
std::iota(begin, end, beginVal): fill in[begin, end)with{beginVal, ++beginVal, ...}std::adjacent_difference(begin, end, dstBegin, Op = std::minus): as its name, output{val[0], val[1] - val[0], val[2] - val[1], ...}std::accumulate(begin, end, initVal, Op = std::plus): accumulate all values, returnstd::partial_sum(begin, end, dstBegin, Op = std::plus): output{val[0], val[0] + val[1], val[0] + val[1] + val[2], ...}std::inner_product(begin1, end1, begin2, initVal, Op1 = std::plus, Op2 = std::multiplies): finally getinitVal + a[0] * b[0] + a[1] * b[1] + ...std::reduce(begin, end, initVal, Op = std::plus): same as accumulatestd::inclusive_scan(begin, end, dstBegin, Op = std::plus[, initVal]): same as partial sumstd::transform_reduce(begin1, end1, begin2, initVal, ReduceOp = std::plus, BiTransformOp = std::multiplies): same as inner productstd::exclusive_scan(begin, end, dstBegin, initVal, Op = std::plus): similar to partial, but exclude the element itself, i.e. the sequence is{initVal, initVal + val[0], ..., initVal + val[0] + ... + val[n - 2]}std::transform_inclusive_scan(begin, end, dstBegin, Op, UnaryTransformOp[, initVal])std::transform_exclusive_scan(begin, end, dstBegin, Op, UnaryTransformOp[, initVal])
std::gcd(a, b): 最大公约数std::lcm(a, b): 最小公倍数std::midpoint(a, b): since C++ 20, returna + (b - a) / 2
Parallel Algorithm
- There are two kinds of parallelism
- SIMD: single instruction multiple data 单指令多数据
- SIMT: single instruction multiple threads
- Since C++ 17, parallel-version algorithms are added
- Defined in
<execution>- There are four execution policies defined in
std::executionseq: sequenced policy 完全不并行par: parallel policy 并行unseq: unsequenced policy (since C++ 20) 算法可以适应 SIMDpar_unseq: parallel and unsequenced policy
- There are four execution policies defined in
- There are four kinds of data dependencies
- RAR: read after read 可以使用
par_unseq- E.g.
std::adjacent_find
- E.g.
- RAW: read after write, e.g.
a[j] = a[j - 1] + 1 - WAR: write after read, e.g.
a[j - 1] = a[j] + 1 - WAW: write after write
- RAR: read after read 可以使用
- Parallel algorithms
std::partition,std::nth_elementstd::mergestd::inplace_merge
- There are also some algorithms that cannot be parallelized
- Those who only operate on several values, e.g.
std::min/max/minmax/clamp,std::swap/iter_swap - 随机算法
std::searchstd::push/pop/make/sort_heap- 排列算法
- 二叉搜索算法
- Ordered numeric algorithms, i.e.
std::iota/accumulate/inner_product/partial_sum
- Those who only operate on several values, e.g.
Range-version Algorithms
算法中需要声明迭代器,当操作的是一整个容器时,就需要 begin 和end,所以可以使用ranges。range-version 算法也可以叫做 constrained algorithms,使得算法操作更加灵活
- You can additionally specify projection as the last parameter, i.e. transformation of elements before entering the real function 最后一个参数可以指定一个映射,例如使用 transform 在传入函数前进行变换
- This just changes criteria(标准;条件), the element itself is unchanged
- Multiple ranges may specify multiple projections
1 | |
- Range-version algorithms also have these advantages
- 使用了 C++20 中的 concept
- The range doesn’t need to be comma (i.e.
begin/endwith the same type)begin和end不要求类型相同 - 更加安全
- 有些算法被加强了
- 新的方法加入进来
- 用模板方法更容易
- There are also some defects
- 不能使用并行算法
- 一些算法被削弱了
- 返回值类型并不和
std::相同,返回值改变有以下几种形式stdr::in_in_result<I1, I2>: 本来返回两个迭代器,现在返回了一个结构体,里面的成员变量是两个迭代器stdr::in_out_result<I, O>stdr::in_in_out_result<I1, I2, O>stdr::set_union/intersection/symmetric_differencestdr::merge- binary
stdr::transform
stdr::in_out_out_result<I1, I2, O>stdr::partition_copy
stdr::in_found_result<T>
Lifetime
Storage duration 存储持续性
There are four kinds of storage duration
- Static storage duration: global variables, static variables in a function/class
- Automatic storage duration: variables that belong to a block scope ro function arguments 定义的时候构造,退出的时候析构
- Dynamic storage duration: you can create objects by using or some other allocation functions
- Thread storage duration: 线程创建的时候构造,线程退出的时候析构
The lifetime of an object begins when storage with proper alignment and size is allocated and the object is initialized 合适的对齐,合适的大小,以及初始化
The lifetime of an object ends when it’s destroy, or the dtor is called, or its storage is released or reused by non-nested object 析构函数被调用,存储被释放,被重用(float类型的变量通过某些手段被 int 类型变量占用)
Temporary objects are only alive until the statement ends (i.e. until ;) 临时变量的声明周期只到语句结束之前,也就是 ; 分号之后才结束
- 函数中的参数传递
const&或std::function_ref是安全的 - 返回临时变量可以延长对象的生命周期,例如
const&1
2
3struct A{};
A bar() {return A{};};
const A& a = bar();
In modern C++, pointer is far beyond address; it has type T*, and you can hardly ever access some address by it when there are no underlying objects of type T alive 指针的功能远远超出寻址的语义,指针是带有类型的概念;如果指针指向的地址不符合指针具有的类型,如果再用指针访问相应的元素就会是无效的
Placement new
“就地初始化” ConstructOnBuffet, which won’t allocate memory, but only create the object at the place 不在重新分配内存,直接在现有已开辟的内存空间中创建对象
1 | |
new(buffet) Type Initializer, whereInitializeris optional- Of course, you need to make sure the alignment satisfies the requirement of the type, so you can use keyword
alignas为了保证类型对齐需要用到在 C++ 11 引入的关键字alignas
std::byte: defined in<cstddef>since C++ 17; it’s just an enumeration class and explicitly represents a byte (before we may useunsigned char)- Trivial dtor
- It’s implicitly declared or declared with
=default隐式生成(编译器)的或者被定义为default- It’s non-virtual and all non-static data members have trivial dtor 所有的非静态成员都有 trivial dtor,并且成员不能是虚的
- For example
- ✅
struct A{int a; float b;};- ✅
class A{int a; public: float b; ~A() = default };- ✅
class A{int a; public: float b; virtual ~A() = default };- ❎
class B : public A{};- ❎
class A{~A() {}};- ❎
class A{std::unique_ptr<int> ptr;};
Corner Cases
- Case1: if you construct an object that has the same type as the original object, and they occupies exactly same storage, then the original name, pointers and references are still valid 就像赋值符号一样
- Case2: it’s best to reuse storage of plain types like
intor classes that have trivial dtor 如果要重用内存尽量使用简单的类型,例如int或者带有 trivial dtor 的类,对于其他类型编译器会在退出当前 scope 时候会自动调用析构函数 - Case3: it’s illegal to reuse memory of
constobjects that have determined their value in the compilation time - Case4:
unsigned char/std::bytearray is explicitly regulated to be able to provide storage 这两个类型的数组是明确地可以提供 storage 的 - Case5: It’s legal to access the underlying object by pointers without the same type in these cases (type punning/aliasing 类型堆叠 / 类型别名) 在少数情况下可以使用不同类型的指针访问一些对象
- add/remove cv-qualification
int类型的指针可以使用const int类型的指针访问 - decayed array 用指针访问数组的元素
- if the underlying type is integer, then using the pointer of its signed/unsigned variant to access it is OK
- convert it to
(unsigned) char*/ std::byte*允许将对象视作字节数组 byte array
- add/remove cv-qualification
- Case6:If you have an old pointer where you’ve constructed a new object, but you want to use the old pointer to get the new pointer, you can use
std::launder(洗涤;洗钱) defined in<new>since C++ 17std::launder(reinterpret_cast<A*>(buffer))to get the actual valid pointer 用旧的指针获得指向新的对象的指针
Strict Aliasing Rules
Strict aliasing rules, if pointers are not aliased or not contained as member, then compilers can freely assume that they’re different objects 本质上就是检查两个指针指向的区域有没有可能重叠
1 | |
- Compared with non-member version (i.e.
Unpack(uint8_t* target, char* src, int size)), it’s 15% slower targetis an alias ofthis. It will then always reloadtarget[i]instead of caching aqwordto prevent change oftarget编译器认为target是this的别名
Others
- Attention to lambda lifetime
- Lambda lifetime should always be shorter than reference captures
- If you capture in the class, then this only captures members by
this, which may be invalid after destruction 如果this被析构掉,就算是把this拷贝出来,还是失效的
- Attention to view lifetime
- Sometimes you mey return a view generated by range adaptor in a function (e.g.
v | std::reverse)- For lvalue, it’s same as the lvalue itself, i.e.
vhere - For rvalue, it’ll same as return a value, so that it’s always safe 临时值
- For lvalue, it’s same as the lvalue itself, i.e.
- 所有的 range adaptors 在调用之前都会调用
stdv::all尝试将 range 转换成 view;但是对于 view 来说不做任何事情- For lvalue range, it’ll create a
stdr::ref_view - For rvalue range, it’ll create a
stdr::owning_view
- For lvalue range, it’ll create a
- Sometimes you mey return a view generated by range adaptor in a function (e.g.
Type Safety
Implicit Conversion
- Some implicit conversions are automatic (standard conversions), and others are user-defined 很多隐式的转型都是自动的
- E.g.
operator float(). If you declare it asexplicit, then implicit conversion will be disabled
- E.g.
- Standard conversions
- Lvalue-to rvalue conversion, array-to-pointer conversion, function-to-pointer conversion
- Decay actually means
- Array/Function -> pointer
- Or for other types, remove remove references first, remove cv-qualifiers(const & volatile) next
- You can use
std::decay_t<T>to get the decayed type auto a = xx;will also decay the deduced type, whileauto&will not- But structured binding
auto [a, b] = xx;“seems” not decay decay 看似没发生,其实是发生在结构化绑定的实现上,相当于auto anonymous = xx;,a和b是成员变量的别名,decay 发生在anonymous中
- But structured binding
- Decay actually means
- Numeric promotions and conversions
- Promotion: promotion has higher precedence and will not lose precision
b + cwherebandcareunsigned shortwill in fact silently promote them tointand then do+先提升到int然后再做加法- 至少提升到
int floatcan be promoted todouble
- Signed value has negative values while unsigned ones don’t, but conversion may happen
floatcannot represent allint/...butintcan be converted tofloatimplicitly- Any scalar types can be converted to
bool - Pointers can be converted to
void*to base class, andnullptrcan be converted to pointer directly - Pointer to member of derived class can also be converted to pointer to member of base class, i.e.
Derived::int*->Base::int* - There are also some numeric conversions that need explicit cast 数值上的转换需要显示的转换
- Narrow integer conversion will mod
例如 int->short,long long->int会把高位的位数截断 - Narrow floating conversion will be rounded
- Floating to integer will truncate the digits after dot; UB if truncated integer is not representable by converted type
- Narrow integer conversion will mod
- Promotion: promotion has higher precedence and will not lose precision
- (Exception-specified) function pointer conversion
- 可以把
noexcept的函数指针转换成没有noexcept的函数指针
- 可以把
- Qualification conversions
- You can convert a non-const/non-volatile to const/volatile one
- Lvalue-to rvalue conversion, array-to-pointer conversion, function-to-pointer conversion
Static Cast
static_cast is the most powerful one, which can process almost all of normal conversion,defined as static_cast<TargetType>(Exp)
Standard-layout
- 所有的成员都有相同的访问属性
- 没有虚函数
- The base class is not the type of the first member data 基类对象不能是子类第一个成员变量
- 整个继承结构,只能有其中一个类是有非静态的变量
- All implicit conversions can be explicitly denoted by
static_cast可以做任何一种隐式的转换,也会允许逆操作 e.g.int->short,double->float - Scoped enumeration can be converted to/from integer or floating point, which is same as the underlying integer type
- Inheritance-related conversions
- upcast 向基类转换;更安全的
- downcast 向派生类转换;有点危险
- For
static_cast, besides inheritance-related pointer conversion, it also processesvoid*- You can convert any object pointer to
void*(this is also implicit conversion) - You can also convert explicitly
void*to any object pointer 前提是对象潜在的类型U和指针的类型T有某种特殊的关系——pointer-interconvertibleT == UUis a union type, whileTis type of its memberUis standard-layout, whileTis type of its first member or its base class- Or all vice versa/transitivity
- You can convert any object pointer to
- 并不保证地址是相同的
- Convert to
void: just discard value, nothing happens - Construct new object: if the object ctor can accept a single parameter, which is convertible from the expression, then it in fact constructs a new object. E.g.
static_cast<A>(a)forA(int) - Transform value category
static_castcan be used to specify which overload of functions is used by function-to-pointer conversion
Dynamic Cast and RTTI
Dynamic Cast
static_cast在继承链中检查是非常弱的(可以说是不做检查),即便转换的对象不是派生类的类型仍然会做转换,只是会带来 undefined behavior。dynamic_cast尝试解决这个问题,如果转换不合适会失败
- 引用上转换失败会抛出异常
throw std::bad_cast - 指针上转换失败会返回
nullptr - 比 UB 更强,更容易定位 bug
为了做了运行时检查,C++ 编译器会在文件中保留运行时的类型识别(RTTI, Run-Time Type Information/Identification),dynamic_cast只能用在多态的类型转换中,因为 RTTI 依赖于虚指针等特性。但是 dynamic_cast 性能上要比 static_cast 慢 10 倍甚至百倍
- You can do downcast in polymorphic types
- 被转换的对象,潜在的对象类型必须和基类的类型相同,否则不能转换成功
dynamic_cast不能用在当前类构造函数和析构函数中,因为当前类的虚指针不是完整的
- You can also do sidecast in polymorphic types with multiple inheritance
RTTI
C++ 提供了一种方式可以直接得到类型的信息,定义在 <typeinfo>,同样要限制使用,会造成性能上的问题。可以使用typeid(xxx) 得到 const std::type_info,类似于sizeof 操作符。type_info是只读的,不能通过拷贝或者构造,只能通过 typeid 获得或者引用。可以使用 .name() 进行 debug
.name().hash_code().before()
RTTI is unfriendly to shared library 对动态链接库不是友好的
- Since GCC 3.0, symbols are compared equality by address instead fo names. So to preserve only one symbol across many
.objfile, it merges them when linking (like in static library) 符号使用地址比较相等性,而不是通过名字比较相等性;即使两个符号的名字是相等的,地址不相等,当出现在不同的.obj文件中的时候,会将名字相等的符号进行地址合并 - So to load shared library quickly, many procedures are omitted, which includes resolving different RTTI symbols 为了快速链接动态链接库,很多步骤都要被省略,其中也包括 RTTI 符号的合并
Const Cast
- It tries to drop the cv-qualifiers
- 明确的知道了原来的对象就是非 read-only,然后接收到的对象是
const类型的 - The author forgets the
constin parameter, but it in fact doesn’t write it
- 明确的知道了原来的对象就是非 read-only,然后接收到的对象是
volatileis similar 把volatile去掉会有 cache 的风险,volatile要求每次使用都要到内存中重新去读- 一般情况下用不到
Reinterpret Cast
reinterpret_cast is used to process pointers of different types, which is dangerous because of life time
- Converting from an object pointer to another type, i.e.
reinterpret_cast<T*>(xxx)- This is same as
static_cast<T*>)(static_cast<(cv) void*>(xxx)) std::launder
- This is same as
- Converting from a pointer to function to another type of pointer to function; or pointer to member to another one
- Converting pointer to integer or vice versa (反之亦然)
- A pointer can be converted to integer by
reinterpret_castif the integer is large enough (std::uintptr_t) - This integer can be converted back to get the original pointer
reinterpret_castfrom0/NULLis UB- Reference is also convertible 引用和指针一样
- A pointer can be converted to integer by
Type-safe union and void*
Since C++ 17,
<variant>and<any>are introduced to guarantee the safetystd::variantcan be seen as aunionwith asize_tindex, which will inspect whether the member is in its lifetime when getting1
2
3
4
5
6
7
8std::variant<int, float, int, std::vector<int>> v{1.0f };
// 类似于
union Union {
int _1;
float _2;
int _3;
std::vector<int> _4;
};- For construction
- By default, the first alternative is value-initialized 默认第一个位置被初始化
- You can also assign a value with the same type of some alternative, then this’s the active alternative
- You can also construct the member in place,i.e. by
(std::in_place_type<T>, args...) - You can construct by index, i.e.
(std::in_place_index<Index>, args...)
- To access or check the existence of alternative
.index(): return the index of active alternative- These methods need the examined type unique in type params
std::hold_alternative<T>(v): return Boolean that denotes whether the active alternative is of typeTstd::get<T>(v): return the active alternative of typeT传入引用std::get_if<T>(v): return the pointer to the active alternative of typeT传入指针
- If not unique, you can also use index-based access:
std::get<I>(v),std::get_if<I>(v)
- Besides type safety, the most important extension of
std::variantthanunionis that it implements visitor pattern
- For construction
std::anycan be seen as avoid*with the original type “stored” magically, so that you’ll fail to grasp(理解;领会) the inner object with the wrong type 可以加载任意的对象1
2
3std::any a{1 };
a = 2.0f;
a = "test";- 承载的对象必须有构造函数,类型会 decay
- You can also default-construct it or call
.reset(), then it holds nothing .has_value()(std::in_place_t<T>, args...)- When you need to get the underlying object, you need to use
std::any_cast<T>(a)or(&a) std::anycan have SBO (small buffer optimization) likestd::function标准库会给std::any在栈上分配比较小的 buffer,存储一些非常小的对象,而不是在堆上分配内存.swap/std::swap/.emplace.type()std::make_any, same as constructingstd::any
Programming in Multiple Files
Remember the compilation procedures of C
- Preprocess, where comments are stripped and macros are processed (so that your
#includecan get the file correctly) - Compile, where each source file is compiled independently 编译
- Assemble; this is not something we care since it just translate assembly to object file 汇编
- Link, to locate symbols that are referred in other TUs(Translation unit) 链接
Preprocessor 预处理器
To be specific, preprocessing can be divided into 6 phases
- Read files and map them to translation character set, which guarantees UTF-7 to be supported 读文件 映射
- Backslashes as the end of line are processed to concatenate two physical lines into a single logical line 处理反斜杠
\ - Comments and macros are extracted, and the whole file is parsed
- Preprocessor runs to process all macros
- String literals are encoded as specified by the prefix 处理字符串常量,按照指定的前缀进行编码
- Adjacent string literals are concatenated ;邻近的字符串拼接
A preprocessing directive begins with #. There are four kinds of directives
#include ..., which copies all file content into the current file#include <...>#include "..."
#definei.e. macros, which does pure text replacement#define FUNC(a, b) a + bParameters of macros can be blank
Parameters of macros are directly parsed by commas when no paratheses surrounded, e.g.
FUNC(SomeFunc<int, double>())->SomeFunc<int + double>()用,直接进行分词,遇到,就会替换You need to add an additional pair of paratheses to help parse, e.g.
FUNC((SomeFunc<int, double>()), 3)You can use
...for parameters of any number, and reference them by__VA_ARGS__变长参数的替换Since C++ 20, you can use
__VA_OPT__(content), which will be enabled only when__VA_ARGS__is not empty#can be used to turn parameters to strings, and##can be used to concatenate parameters to make them a whole token1
2
3
4
5
6#define NameToStr(a, b) #a #b
auto str = NameToStr(1, aa)
#define ConcatName(a, id) a ## id
int ConcatName(a, 1) = 0;
std::cout << a1;
You need
#undefto drop the definition of the macro 取消宏定义
Conditional choice of code
#ifdef, (#elifdefsince C++ 23),#else#ifndef, (#elifndefsince C++ 23),#else#if defined xxis equivalent to#ifdef xx#endif#if,#elif,#else
#pragmais in fact a macro for implementation-defined usage 需要查看编译器文档或者其他相关文档才能知道具体的用途#pragma once,#pragma pack
#line: specify the line number manually
Compile
Declaration & Definition
- Translation unit (TU)
- 每一个源文件都是单独进行编译,最后通过连接器去链接未知的符号,每个源文件通过预处理将其他符号加到当前文件中,这一整个处理结果就是 TU
- C++ 要求先声明再使用,所以每个 TU 首先要看到所使用的声明
- C/C++ has One-Definition Rule (ODR), meaning that each entity should have only one definition in a TU or even in a program 一个实体只能定义一次
- 典型的声明和定义
- Function prototype & one with function body 函数签名和具有函数体的函数,也包括类的成员函数
class A;,class A{...},struct类的声明和定义enum class A (: Type)
- 类的声明是一个比较特殊的实体,对于函数来说只需要暴露函数的签名就可以使用,但是对于类来说声明是远远不能够使用类
- It only requires the class to be defined only once in a TU
- Besides, class definition requires to fully see all definitions of its members & base classes 类的定义必须要求有完整的定义,包括类的成员和基类
- You cannot
class Vector3; class A {Vector3 v;}; - This is because compilers need to determine the layout of the class; if definition of some members are unknown, its
sizeofis unclear 编译器必须知道类的大小
- You cannot
- We can use mere class declarations in these cases 只需要使用类的声明的情况
- As an argument of prototype; its members and layout are not used 做为函数的参数
- When you only needs a pointer or reference as members 用指针或者引用指向类
- Notes
- It’s allowed to put definition of methods into class definition
- Return types and parameter types of declarations and definitions of methods should be the same
friendwill implicitly declares the class or function- Class members in class definition is in fact definition instead of just simple declaration, so we don’t need to define it again in .cpp
- Default parameters of functions should be put into declaration, and shouldn’t be put into definition
- Type alias (like
using) andstatic_assertare also declarations - header guard 解决定义出现两次的问题
#pragma once
- Template 的声明和定义
- Template will not preserve its information to object file
- 在头文件中写声明和定义
- Function template in class should also be put into header
Namespace
When code base is large, name conflicts usually happen 解决命名冲突,C 语言中解决方式是加大量的前缀
using namespace xxis likefrom xx import *using yy::xxis likefrom yy import xxYou should never put
using namespace xxxorusing xxinto header filesInline namespace has nothing to do with
inline. It’ll expose contents into the parent namespace, as if there is ausing namespace xx和关键字inline毫无关系,目的是把所包含的内容暴露到上层命名空间中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16namespace Test6
{
inline namespace Implv1
{
void Func();
}
}
namespace Test6::Implv1
{
void Func()
{
std::cout << "This is v1.\n";
}
}
// 调用的时候完全可以将 `Implv1` 忽略掉
Test6::Func();老代码需要兼容,新代码可以平滑过渡
Inline
- Recall procedures of function calls
- Caller saves registers on the stack
- Jump to the calling position 跳转到函数所在的地址
- Callee saves registers, execute code, and restores registers 对于函数本身来说也会保存寄存器,并执行代码,在把寄存器中的内存恢复
- Jumping back by popping up the return address
- Caller restores registers on the stack
- If we can fuse function body into the caller and optimize together, then register saving / restoring and jumping will be almost eliminated 直接将内联函数插入到调用的地方,寄存器的保存和恢复,以及跳转的开销会被消除以达到优化的目的
- Inline function should be put into header files 因为每个源文件都需要知道内联的函数体
inline也会造成其他问题- The code size may bloat(膨胀), since the function body is inserted everywhere
- Utility of instruction cache may be lower, since the same function has different addresses 对 i-cache 的利用率降低,相同的代码具有完全不一样的地址
- Inline function won’t create their function address, so you cannot “jump to the next” when debugging 进行 debug 时把整个函数跳过去了
inlineis just an suggestion to compiler, and compiler may choose to not inline the body- 递归调用
- 函数本身逻辑比较复杂
- 不知道什么时候使用
inline合适
- Since C++ 17, inline variables are introduced 内联变量,可以直接把内联变量放到头文件中
- This mainly facilitates header-only libraries, since they hope to use some global variables without source files
- Inline variables can also be in class definitions, so that
staticvariable can be unnecessary to split definition and declaration 静态变量就不需要分开声明和定义了
- Inline functions/variables may cause double symbols in shared libraries 内联函数 / 变量会在动态链接是造成双定义
- 静态链接库是需要完全的符号合并
- 但是动态链接库的符号是未必进行合并的 RTTI
- 在链接库的内外会存在两个版本的变量
Linkage
External linkage: Linker can always find the symbol in other TUs 链接器在大多数情况下都能在其他的 TU 中找到相关符号,这种的叫做外部链接,几乎所有的实体在不加关键字的情况下,都是 external linkage
- Class members
- Functions
- Functions declared by
friend - Enumerations
- Templates
- Non-const variables, volatile variables and inline variables
Internal linkage: 但是有的时候不想暴露实体,使用外部链接会让其他 TU 窃取实现的私密性
staticin introduced to force internal linkage 用static关键字声明内部链接性实体- Unlike static member functions,
staticthat denotes linkage is necessary in definition 在函数定义时需要带上static,成员函数则不需要 - 外部链接性和模板实例化不会冲突,完全是两个不相干的概念
- Unlike static member functions,
- Another way is to define things in an anonymous namespace 需要定义大量的内部链接性实体时候可以使用
- There are some special cases where entities are born with internal linkage
constglobal variables- Anonymous unions
Singleton
- Reason
- The sequence of initializing global variables across TU isn’t determined 全局变量初始化的顺序在同一个 TU 中可以保证,但是在不同的 TU 中不能保证
- Side effects caused by global variables may not be executed
1 | |
- No linkage 无链性
- This happens for static local variables (i.e.
staticvariables in functions) and normal local variables - You can even define a class inside the block scope, which also has no linkage
- This happens for static local variables (i.e.
XMake
XMake acts as both a build tool and a package manager
(Optional) Project name, project version and required xmake version
1
2
3set_project("Programming in Multiple Files")
set_xmakever("2.8.1")
set_version("0.0.0"Modes and language version
1
2add_rules("mode.debug", "mode.release")
set_languages("cxx20")Some other options
1
2set_policy("build.warning", true)
set_warning("all")set_policy("build.warning", true)means that report warning even if compile success
Add required packages
add_requires("ctre 3.8.1", "catch2")Specify the building target
1
2
3
4target("example")
set_kind("binary")
add_headerfiles("example1/*.h")
add_files("example1/*.cpp")target(name)set_kind(...)binarywill compile the executablestaticstatic librarysharedstared library/dynamic-linked libraryphonyempty, just used to combine targets like librariesheader_onlyfor projects that only have header files
add_files(...)add_headerfiles(...)
xmaketo compile all targetsxmake -b xxto compile specific targetsxmake run xxto run specific executable
Modules
There are several problems in headers
- Non-inline functions cannot be defined to keep ODR
#includealways requires the preprocessor to copy all contents, which makes the real file huge and drags the compilation stage- If marcos aren’t undef, they will be leaked
Every module has only one primary interface unit
Begin with
export module Name在文件开始时声明It regulates that entities are visible to other modules by
export文件中的其他实体都可以加export关键字Module interface files have no determined suffix
- msvc - ixx
- clang - cppm
- gcc - don’t care
- It can also be mmp, mmx
export import字面意义Modules 也允许声明和定义分离,原理是 module implementation unit
- It begins with
module Name;and shouldn’t have anyexport - A module can have multiple implementation files, as long as they all begin with
module Name;一个模块可以有多个源文件去实现 - You can directly
import "xxx.h"; they’re called header unit - C++ uses global module fragment
- It begins before
export module Name;ormodule Name;
- It begins before
1
2
3
4
5
6module; // global module fragment
#define NEED_PARAM
#include "Old.h"
module Person; //- It begins with
You can partition either interface or implementation 如果模块太大也可以进行拆分
- Interface partition unit: begin with
export module Name:SubName; - Implementation partition unit: begin with
module Name:SubName2; - 分区时模块内部的概念,对其他模块是透明的
- Inside the module, it can use
import :SubNameto import the partition - But in other modules, they cannot use
import Name:SubName
- Inside the module, it can use
- Unlike module implementation, implementation partition is not implementation of interface partition 模块的实现分区和模块的接口分区并不是实现的对应关系,不能在出现同名的分区了
- If there exists
module A:B; there shouldn’t existexport module A:B
- If there exists
- Partitions cannot have partitions (depth == 1) 分区不能再进行分区
- Interface partition unit: begin with
Error Handling
Error code extension
Optional
It uses an additional
boolto denote “exist or not” 用bool值来表示是否存在Empty value then introduced as
std::nullopt, which essentially makes the underlyingboolto be thefalse1
2
3
4
5
6
7template<typename Key, typename Val>
std::optional<Val> Get(const std::map<Key, Val>& map, const Key& key)
{
if (auto it = map.find(key); it != map.end()
return it->second;
return std::nullopt;
}
Ctor,
operator=,swap,emplace,std::swap,std::make_optional- Ctor can also accept
(std::in_place, Args to construct T)
- Ctor can also accept
operator<=>std::hash; unlikestd::variant, it’s guaranteed forstd::optionalto have the same hash asstd::hash<T>if it’s notstd::nulloptYou can just use
std::optionalas a nullable pointeroperator->/operator*/operator bool, as if a T*- The behavior is undefined for
->/*if it’s in factstd::nullopt
- The behavior is undefined for
.has_value(),.value()(which will throwstd::bad_optional_accessinstead ofstd::nullopt).value_or(xx)can provide a default value
Note
- Most of types in Java and C# are nullable, which makes them “optional” automatically 像是 Java 和 C# 语言大部分的变量类型都是自动的”optional”,但是也会有效率上的问题
std::optional,std::expected,std::anyandstd::variantare sometimes called “vocabulary type” 它们都不能用作引用类型去实例化模板std::optional<int&>- Though
std::optionalonly store an additionalbool, this alignment and padding will make it in fact larger
Expected
- It uses an Error type (i.e.
std::expected<T, E>) instead ofnullto denote absent value 用第二个模板参数来表达错误类型,更被建议用作错误处理
1 | |
Monad
<T1, E1>.and_then(T1)needs to return<T2, E1>- For
std::optional, it’s obligated to returnstd::optional<T2>
- For
<T1, E1>.transform(T1)needs to returnT2, which will construct<T2, E1>automatically- For
std::optional, it’s obligated returnT2, which will construct<T2>
- For
<T1, E1>.or_else(T1)needs to return<T1, E2>- For
std::optional, it’s obligated returnstd::optional<T1>
- For
<T1, E1>.transform_error(E1)needs to returnE2, which will construct<T1, E2>automatically
1 | |
Exception
- Exception is a technique that will automatically propagate to the caller if it’s omitted 异常可以将调用者忽略的错误自动地传递给更上层的调用者
- For example, function chain A -> B -> C -> D, if D throws an exception, and D doesn’t catch it, then C needs to do so; if C doesn’t, B needs to do so; etc.
try - catchblock to catch an exception
1 | |
.what()is a virtual method ofstd::exception
- Note
- You only need to catch exception when this method can handle it
- Though you can throw any type, it’s recommended to throw a type inherited from
std::exception- Reason: base class can also match derived class exception to catch it, so you can always
catch(const std::exception&)and print.what()to know information
- Reason: base class can also match derived class exception to catch it, so you can always
- Catch block is matched one by one catch 块是线性的进行的
- Though it’s allowed to catch with or without
const/&, exception should definitely be caught byconst Type& - If you’re in a
catchblock and find that the caught exception still cannot be handled, you can use a singlethrow;to throw this exception again 不能处理异常可以继续往上抛出,最好不抛出异常对象 - If another exception is thrown during internal exception handling (e.g. dtor throw an exception during stack unwinding),
std::terminatewill also be called 在处理异常的时候由出现了异常会直接终结,不可能在异常中再重新抛出异常了
Exception Safety
Exception safety means that when an exception is thrown and caught, program is still in a valid state and can correctly run 当异常被抛出并且被捕获后,程序依然处于有效状态并且正确运行
No guarantee 没有异常安全性
- 资源或内存泄漏
- 不变量被破坏
- 内存发生了损毁,一片内存写了一部分就发生了损坏并退出了程序
Basic guarantee: at least program can run normally, no resources leak, invariants are maintained, etc
RAII is a really important technique for basic guarantee
解决方案是使用析构函数 use destructor
RAII (Resource acquirement is initialization): acquire resources in ctor and release them in dtor 在构造函数里申请资源,在析构函数里释放资源,这就是 RAII
std::unique_ptrto manage heap memory instead ofnew/deletestd::lock_guardto manage mutex instead oflock/unlockstd::fstreamto manage file instead ofFILE* fopen/fclose- 自己编写的类也要符合 RAII 的原则
To sum up, all members that have been fully constructed will be destruct, but dtor of itself won’t be called 只有在构造函数中完全初始化(没有异常)析构函数才会执行
1
2
3
4
5
6
7
8
9MyData(int id) : ptr1{nullptr }, someData{nullptr } {
auto init_ptr1 = std::unique_ptr<int>{new int {id} };
auto init_someData = std::unique_ptr<int>{new int {id} };
// will never throw below
ptr1 = init_ptr1.release(); // release ownership, so dtor of
someData = init_someData.release(); // unique_ptr does nothing
}
~MyData() { delete ptr1; delete someData; }- 指针抛出的异常是
std::bad_alloc new(std::nothrow)will returnnullptrinstead of throwing exception. e.g.new(std::throw) int{id}但是仍然需要判断nullptr
- 指针抛出的异常是
Strong exception guarantee 强异常保证,当函数抛出异常后,程序能够回滚到原来的状态
Most of methods in STL obey strong exception guarantee
std::vector::push_back(),std::vectorhas same elements as before even if exception is thrown 当插入元素失败的时候,原来vector中的元素还存在
A technique to maintain strong exception guarantee in assignment operator is copy-and-swap idiom 拷贝交换惯用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27template<typename T>
class Vector
{
public:
Vector(std::size_t num, const T& val)
{
std::unique_ptr<T[]> arr{ new T[num] };
std::ranges::fill(arr.get(), arr.get() + num, val);
first_ = arr.release();
last_ = end_ = first_ + num;
}
std::size_t size() const noexcept {return last_ - first_; }
auto& operator[](std::size_t idx) noexcept {return first_[idx]; }
const auto& operator[](std::size_t idx) const noexcept {return first_[idx]; }
Vector(const Vector& another)
{
auto size = another.size();
std::unique_ptr<T[]> arr{ new T[size] };
std::ranges::copy(another.first_, another.last_, arr.get());
first_ = arr.release();
last_ = end_ = first_ + size;
}
private:
T* first_, *last_, *end_;
};如何实现
operator=1
2
3
4
5
6
7
8
9
10Vector& operator=(const Vector& another)
{
delete[] first_; // 只是放指针所指向的内存
auto size = another.size();
std::unique_ptr<T[]> arr{ new T[size] };
first_ = arr.release();
std::ranges::copy(another.first_, another.last_, first_);
last_ = end_ = first_ + size;
return *this;
}如果
new抛出异常,尽管内存已经释放掉了,但是first_和end_仍然不变,所以.size()依然不变1
2
3
4
5
6
7
8
9
10
11Vector& operator=(const Vector& another)
{
delete[] first_;
first_ = last_ = end_ = nullptr; // 将指针也释放掉
auto size = another.size();
std::unique_ptr<T[]> arr{ new T[size] };
first_ = arr.release();
std::ranges::copy(another.first_, another.last_, first_);
last_ = end_ = first_ + size;
return *this;
}如果
std::ranges::copy出现了异常,那么first_,last_,end_状态又是不一致的,first_被先赋值的1
2
3
4
5
6
7
8
9
10
11
12Vector& operator=(const Vector& another)
{
delete[] first_;
first_ = last_ = end_ = nullptr; // 将指针也释放掉
auto size = another.size();
std::unique_ptr<T[]> arr{ new T[size] };
std::ranges::copy(another.first_, another.last_, first_);
// only release when all exceptions are possibly thrown!
first_ = arr.release();
last_ = end_ = first_ + size;
return *this;
}满足了基本异常安全的保证,但是不满足强异常安全性的保证,必须保证释放资源是在所有可能抛出异常语句的后面
1
2
3
4
5
6
7
8
9
10Vector& operator=(const Vector& another)
{
auto size = another.size();
std::unique_ptr<T[]> arr{ new T[size] };
std::ranges::copy(another.first_, another.last_, first_);
delete[] first_;
first_ = arr.release();
last_ = end_ = first_ + size;
return *this;
}除了
delete[]其他的和构造函数几乎一样,可以换一种方式实现1
2
3
4
5
6
7
8
9
10
11
12friend void swap(Vector& vec1, Vector& vec2) noexcept
{
std::range::swap(vec1.first_, vec2.first_);
std::range::swap(vec1.last_, vec2.last_);
std::range::swap(vec1.end_, vec2.end_);
}
Vector& operator=(const Vector& another)
{
Vector vec{another};
swap(vec, *this);
return *this;
}- Allocating memory before releasing, which increases peak memory
- Swap cost it slightly higher than direct assignment
- May be not optimal for performance
Exception safety of containers
- All read-only &
.swap()don’t throw at all 所有只读方法和.swap()都不抛出异常,除了故意抛出异常的函数 - For
std::vector,.push_back(),emplace_back(), or.insert/emplace/insert_range/append_range()only one element at back provide strong exception guarantee - For
std::list/forward_list, all strong exception guarantee 因为内存不是连续的,所有的方法都会保证强异常安全性 - For
std::deque, it’s similar tostd::vector, adding push at front - For associative containers,
.insert/...a node only a single element has strong exception guarantee
- All read-only &
Strongest exception safety 最强异常安全性:一个方法永远都不会抛出异常可以加上
noexcept标识符- If your function is labeled as
noexceptbut it throws exception, thenstd::terminatewill be called noexceptis also an operator 也是一个运算符,用 evaluate 函数是否标记了noexcept标识符- IMPORT: destructor & deallocation is always assumed to be
noexceptby standard library 标准库永远假设析构函数和释放行为不会抛出异常- Dtor is the only function by default
noexceptwithout any explicit specifier if all dtors of members arenoexcept - 编译器自动生成的构造函数或赋值函数也是
noexcept
- Dtor is the only function by default
- Since C++ 17, noexcept function pointer is also supported C++ 17 支持了函数指针用
noexcept标识 e.g.using Ptr = void(*)(int) noexcept; Ptr ptr = square;不能指向可以抛出异常的函数 - General rule: for normal methods, only when the operation obviously doesn’t throw should you add
noexcept- Merely read-only methods in containers (like
.size()) are marked asnoexcept
- Merely read-only methods in containers (like
- If your function is labeled as
When to use exception
- Exception is relatively costly compared with other error handling mechanisms, like it relies on heap allocation 相对于其他错误处理机制代价更高,需要保证抛出异常发生情况是极少数的情况;只有在抛出和捕获的时候才有开销
- Besides, in current typical implementations, stack unwinding of exception needs a global lock, which is really unfriendly to multi-threading programs 对多线程不友好
- Also, exception is highly dependent on platform (just like RTTI)
Assertion
Assertion is a technique to check expected behaviors of functions or code segments when debugging
- When the parameter is evaluated to
false, program will be abortedstd::abort()is the default behavior ofstd::terminate(), but latter can change its behavior bystd::set_terminate_handler(...)- It’s a macro defined in
<cassert>
assert用作没有副作用行为的条件检查assertis done in runtime; if you want to determine in compile time, you can use keywordstatic_asset(xx, msg),msgcan be omitted since C++ 17- 通常用于内部的方法,检查已应过滤掉,但是仍然会出现的非法的情况,用于在 debug 中定位问题
- Assertion 在安全检查方面是非常有限的
ContractC++ 26 is likely to addcontract, which will enrich it a lot
Debug Helpers
Source Location
Before C++ 20, we may use maros
__FILE__and__LINE__, which will be substituted to source file name and line number1
2
3
4
5
6
7
8
9static void CheckError(cudaError_t error, const char* file, int line)
{
if (error == cudaSuccess)
return;
std::cerr << "Cuda Error at file" << file << "line :" line << ":" << cudaGetErrorString(error);
exit(EXIT_FAILURE);
}
#define CHECK_ERROR(error) (CheckError((error), __FILE__, __LINE__))__FILE__和__LINE__是不能用在CheckError的默认参数中的,因为这两个宏是在预处理的时候确定的,而不是在调用的时候确定的Since C++ 20,
<source_location>is added to solve itvoid logError(std::string_view errorInfo, std::ostream& logFile = std::cerr, const std::source_location& location = std::source_location::current());
1
2
3
4
5
6void logError(std::string_view errorInfo, std::ostream &logFile = std::cerr, const std::source_location &location = std::source_location::current())
{
logFile << std::format("In file {} function {} - line {}, Error :\n{}\n",
location.file_name(), location.function_name(), location.line(), errorInfo);
return;
}
stacktrace
- Since C++ 23, in
<stacktrace> - Similar to
source_location, you needstd::stacktrace::currentto get it; but you may print it directly
- Since C++ 23, in
debugging, Since C++ 26, in
<debugging>
Unit Test
Catch2
A C++ unit test framework - Catch2
- Catch2 uses macro, so still remember to add paratheses for comma
- Catch2 overloads
operator&&andoperator||, so using them won’t be short-circuit- Thus, you may need to split it to multiple
REQUIRE
- Thus, you may need to split it to multiple
SECTIONcan be generated dynamically; you just need to ensure they have different names
String and String View
- 常量字符串类型
const char[]赋值给auto类型会退化为const char*,C++ 中不能将const char[]赋值给char*,除非使用const_cast - 可以使用空格或换行来连接两个字符串常量 e.g.
"123" "456"和"123456"一样,编译器编译的时候会进行拼接 - Raw strings: 任意字符都不会被转义 escaped
\\\n\"在普通字符串解释为\\n",但是用裸字符串表示R"(\\\n\")"就是 6 个字符- 例如 Windows 系统中的文件路径
- 裸字符解析主要是通过匹配
"(和')"',但是可以在"和(或)之间加入任意其他通配符配合将中间的字符部分解析为裸字符串 e.g.R"+(I want a)"!)+"
String
std::string是std::vector<char>的加强版- 很多方法和
std::vector一模一样 - 提供了
.length()函数,和.size()一样,只是 length 是更常见命名习惯 .append,.append_range和insert(str.end(), ...)一样,但是不能插入一个字符串,返回值是对 string 的引用.assign,.insert,.erase,.append都提供了下标的版本.starts_with,ends_with(C++ 20);contains(C++ 23).substr(index(, count)): 从index开始到count结束,count默认是std::string::npos,会创建新的对象.replace: replace part of the string with a new string same as sub-string.data(),.c_str(): get the underlying pointer- C++ 17 之后
.data()返回的是char*,而不是const char* .c_str()返回的是const char *
- C++ 17 之后
- Search
- 如果找不到则返回
std::string::npos,也就是static_cast<size_t>(-1)一个很大的数 .find(),rfind(): 正向查找或逆向查找find_first_of(),find_first_not_of(),find_last_of(),find_last_not_of()
- 如果找不到则返回
- Notes
find()时,使用不等号来判断是否找到,而不是用>,>=,<,<=std::stringguarantees the underlying string is null-terminatedstd::string可以存储'\0'
std::stringhas SSO (small string optimization) 段字符串优化- 当 string 非常小的时候可以放到栈上而不是放到堆上,降低内存分配
- 具体 string 在栈上可以容纳多少字符是由标准库实现的;在 x64 libstdc++/VC 上是 15,在 libc++ 上是 22
- C++ 23 introduces another optimization for resizing
- Resize 通常需要用固定的字符(例如
'\0')去填充,通常需要reserve和insert两个步骤,性能上会有损耗 .resize_and_overwrite(newSize, Op)意义更明确,并且是覆盖
- Resize 通常需要用固定的字符(例如
- 和数字进行相互转换
std::stoi/sto(u)l/sto(u)ll(string, std::size_t* end = nullptr, int base = 10)- It will stop at the end of the first parsed number, and try to write the stop index to
*end在结束之前解析好,解析失败会抛出异常std::invalid_argument
- It will stop at the end of the first parsed number, and try to write the stop index to
- Base(进制) can be 2 - 36 按照字母表的顺序添加;
base=0时会根据字符串前缀自动解析进制大小- 前缀时
0是八进制 - 前缀是
0x是十六进制
- 前缀时
std::stof/stod/stold(string, std::size_t* end = nullptr)std::to_string()
String View
如果在函数中仅仅是读取一个 string,就会用 const std::string& 作为参数,如果传入的是 C-string 类型,就会构造一个临时的 string 对象,这种情况可以使用std::string_view(C++ 17)。可以理解为本身就存储了一个const char*
.substr返回的仍然是std::string_view而不是std::string- 不支持
operator+ std::string_viewis not required to be null-terminated 都是通过 length 识别长度的- The pointer it contains can be
nullptr- C++ 23 开始不能使用
nullptr进行构造
- C++ 23 开始不能使用
- 当
std::string_view做为返回值时,注意指针悬垂的问题- 返回
std::string是安全的
- 返回
- 作为模板参数时也要注意声明周期
User-defined literals 用户定义自变量
- 类似数值类型
1ull表示数字1是unsigned long long类型的,字符串对象也可以使用用户自定义变量 std::string:"PKU"sstd::string_view:"PKU"sv1sfor seconds,1.1msfor milliseconds,1dfor a day1ifor pure imaginary number 复数,1.2if,2.5id- Remember
using namespace std::literals;in your local scope - 也可以自己定义用户定义自变量
constexpr unsigned int operator"" _KB(unsigned long long m) {return static_cast<unsigned int>(m) * 1024; }- The parameter type is limited 参数类型的限制
- 对整数来说只支持
unsigned long long,最大的整数类型 - 对浮点数只支持
long double - 对字符
char - 对 C-strings
const CHAR*, std::size_t - 最后兜底(fallback)类型是
const char*
- 对整数来说只支持
charconv
stoi/to_stringwill create newstd::string; we may want to provide storage ourselves- E.g.
stoi(std::string{view})is costly, since we only read the string 耗费资源 - Also, they may throw exceptions, which are expensive sometimes 抛出异常也很耗费资源
- E.g.
You can use
std::from_charsandstd::to_charsin<charconv>std::from_chars(const char* begin, const char* end, val)will try to save the result intoval(an integer or a floating point)- It returns
std::from_chars_result, which includes.ptras stopping point and.ecas error code - When
ec == std::errc{}, success; it’s also possible thatec == std::errc::invalid_argument, orstd::errc::result_out_of_range - You can use structured binding, e.g.
if(auto [ptr, ec] = xx; ec != std::errc{}).
std::from_chars(const char* begin, const char* end, val)will try to save the result intoval必须以数字开头base/std::chars_format进制或格式
std::to_chars(const char* begin, const char* end, val)will try to writeval(an integer or a floating point) into[begin, end)base/std::chars_format
Unicode
- UTF-32: make each character occupy 32 bits; it’s direct but useful, since at most 4 billion characters can be used
- But it may occupy too much space, e.g.
abcneeds only 4 bytes before, but currently 16 bytes! - It also needs BOM
- But it may occupy too much space, e.g.
- UTF-8: to solve space waste, UTF-8 uses code with varying length
- Different character length has different coding prefix (like Huffman tree that we’ve learnt) to ensure no ambiguity
- This makes it waste some code space, so some characters may need more than 4 bytes
- For example, ASCII characters, including null-termination ‘\0’, still occupy 1 byte in UTF-8 (the coding is same too) 兼容之前的 ASCII 字符的
- UTF-8 is the most commonly used character set in modern systems
Notice that UTF8 doesn’t need BOM, but Windows identifies Unicode by BOM long long before (UCS-2 needs that), and it has been part of Windows and hard to change, so Windows may require you to give UTF8 a BOM
UTF-8 是单字节并不需要 BOM,但是 Windows 需要 BOM 去识别是不是 Unicode
- Unicode has these basic elements:
- Byte, i.e. computer representation
- Code unit, i.e. (byte count ÷ minimal bytes) used to represent a character (1 for UTF-8, 2 for UTF-16, 4 for UTF-32) 一个 code unit 并不一定是合法的字符
- Code point, i.e. each Unicode character
- Text element, i.e. what humans really see on the screen
Unicode Support in C++
- There are
char8_t/char16_t/char32_tfor UTF-8/16/32, but it’s used as one code unit, instead of one code point- They’re at least 8/16/32 bits to hold one code unit 表示 code unit 比较合适
- You can use
u8/u/Uas prefix separately
But one code point may (and usually) have more than one code unit, so some weird things may happen
1 | |
There are also types like std::u8string, but they are all in code units
- This makes traversal really hard, e.g.
for(auto ch : std::u8string{u8"刘"})will not get刘, but several code units 遍历实际上得到的也是 code unit .size(),.find_first_of()… are also for code unit
- So in fact, e.g.
std::string,std::string_vieware just instantiation of templatestd::string和std::string_view实际上是模板的实例化- More specifically, i.e.
std::basic_string<char>andstd::basic_string_view<char> - So, e.g.
std::u8string,std::u8string_vieware juststd::basic_string<char8_t>andstd::basic_string_view<char8_t> - Since
char8_titself is code unit, the string represents vector of code units too - It also accepts
Traits = std::char_traits<charT>as the second template parameter, which regulates operations used by basic_string like comparison of characters. So theoretically (but usually not used) you can define you own character type as long as it’s standard-layout and trivial, then give aYourStringwith theNewTraits<NewCharType> - You can also provide an allocator, just like STL
- More specifically, i.e.
- Weak Unicode support is mostly due to its complexity C++ 本身提供 Unicode 的支持不是很好,所以需要 Unicode 官方的标准库,或者使用其他的标准库
- C++ core guideline recommends you to use ICU (International Components for Unicode), Boost.Locale, etc. for complete Unicode support
- You may also use utf8cpp, which operates UTF-8 by code point, since ICU is too large for small project
- Besides, input/output Unicode is troublesome in C++ 在 C++ 中 Unicode 的输入输出比较麻烦
- There is also a wide character
wchar_tin C/C++ 宽字符类型(C++ 11 之前)- It’s platform dependent, only regulated that “it has the same property with one of integer types” 内部的表示由平台决定,用正数类型表示其大小
- It’s UTF-16 on Windows, while UTF-32 on Linux
- Prefix for wide character/string literals is
L, e.g.L"爱情可以慷慨又自私" - And, you can also use
std::wcout/wcin/wstring(_view)
1 | |
In fact, C-string or std::string is more like a byte array instead of an ASCII string 事实上 C-string 或者 std::string 本质上是字节数组而不是 ASCII
Locale
- Locale is used for localization
- Each
std::localecontains information for a set of culture-dependent features bystd::facetobjects - Standard facets are divided into six categories:
- Collate: i.e. how characters are compared, transformed or hashed 字符如何进行比较,变换或哈希
- Numeric:
num_get,num_put,numpunctnum_getwill affect howstd::cinworks,num_put->std::cout,numpunctonly affect punctuation 标点符号- For example, in German,
1.234,56means1234.56; if you use Germany locale, then inputting1.234,56will correctly get it instead of1.234
- Time:
time_get/time_put - Monetary:
money_get/money_put/moneypunct财政的;货币的 - Message: transform some error message to another language
- Ctype:
ctype/codecvt, how characters are classified and converted, e.g. is upper 字符如何进行分类,其他字符集如何向其进行转化
- Locale 会影响输入输出流、字符识别和匹配
- Each
- 每个 locale 创建出来都会指向一个实现
- 复制的时候只是复制指针
- 每个实现的数据结构都是
vector<facet*> facet可以复用
Locale is cheap to copy; it uses reference count when copied and points to same set of facets 拷贝的代价很小
Facets use the address of a static member
idto group; e.g. if you want a new facet, you need to inherit fromstd::locale::facetand have staticstd::locale::id id不同的类的实现会Facet will be deleted when it’s never referenced, so
newis correct. It also uses reference countfacet不需要担心内存泄漏的问题,通过引用计数来管理的Create a new group of facet 如何创建新的 facet
1
2
3
4
5
6
7
8class Umlaut : public std::locale::facet {//1
public:
static std::locale::id id; //2
Umlaut(std::size_t refs=0): std::locale::facet(refs) {} //3
bool is_umlaut(char c) const {return do_isumlaut(c);} //4
protected:
virtual bool do_isumlaut(char) const; //5
};
Format
printfis faster thanstd::coutdramaticallyprintfis not type-safe, i.e. type cannot be identified to match%dprintfcannot be customized, but stream can overloadoperator <<- You can use
std::cout << std::format(“a={},b={},c={}\n”,a,b,c)- To print
{or}, you need to use{{` or `}} - You can also specify order explicitly, e.g. like
std::format("c={1}, a={0}, c={1}\n", a, c)
- To print
- C++ 23 introduces
std::print, which also utilizes format std::formatis even faster thansnprintf()- You can write format specifiers after
:, e.g.c={:xx}ora={0:xx}(0is order) - The format is like fill – align – sign - # - 0 – width - .precision – L – type, and all parts are optional
- fill, align, width are used to fill into additional characters to keep a fixed length
- width means the total character numbers (including element itself)
- fill means the character to fill in (by default whitespace)
- align can be left(<), right(>) or middle(^) (by default left, except for integers and floating points to be right)
- For example:
std::format(“{:0^8}”, 1)will get00010000,std::format(“{:08}”, 1)will get00000001 - if element itself is longer than width (e.g. here we pass
10000000), then these specifiers will do nothing - if only a number is given, then it’s seen as width instead of fill
- for most of East Asian characters and many emojis, width is seen as 2 instead of 1
- sign: can be – (default, i.e. only show sign when the number is negative, including -0.0), + (always show sign), and whitespace (only show negative sign, but non-negative number will fill into a whitespace)
- For example,
std::format("{:0^+8}", 1)will get000+1000,std::format("{:+8}", 1)will get+1,std::format("{:}", 1)will get1
- For example,
- type: how to show the element in many forms
- Integer:
b/B/d/o/x/X; by default d(ecimal). Prefix is not output - Particularly,
boolhas an additionals(default), which will gettrue/false char/wchar_thas an additionalc(default), which will get the character; and an additional?since C++ 23, which will output raw character (e.g.\ninstead of a new line)- Floating point:
e/f/g/a/E/F/G/A; by default g(eneral) - Same as
std::chars_format::scientific/fixed/general/hex, while default parameter to precision ofe/f/g/E/F/Gis 6 - String (including C-string, std::string, etc.):
s; by default s- C++ 23 adds a
?, which outputs escaped string (surrounding""will be output too)
- C++ 23 adds a
- pointer:
p; by default p. Same asreinterpret_cast<std::uintptr_t>(ptr)- It will additionally output a
0x - C++ 26 adds a
P, which will force hexadecimal letters to be uppercase
- It will additionally output a
- For example,
std::format(“{:m^+8x}”, 32)will getmm+20mmm;std::format(“{:e}”, 32.F)will get3.200000e+01
- Integer:
- #: alternative form
- For integers with type
x/X/o/b/B, prefix0x/0X/0/0b/0Bwill be added - For floating points, dot will always be shown (e.g.
42.fby default is42, but will get42with#)- Particularly, for explicit
#g/#G, all zeros will be shown, e.g.42.0000
- Particularly, for explicit
- For example,
std::format("{:m^#8x}", 32)will getmm0x20mm;
- For integers with type
- .precision: valid for floating point and string 对浮点数和字符串是有效的
- For floating point, same as
to_chars, i.e. digits after dot - For strings, it’s the maximum characters to output
- For example,
std::format(“{:.4e}”, 32.F)will get3.2000e+01
- For floating point, same as
- 0: fill into 0 for only integers and floating points after sign and prefix (different from fill!), when align isn’t specified
- L: apply locale information on integers and floating points by the current locale (you can also provide
std::localeas the first parameter to specify it) - fill – align – sign - # - 0 – width - .precision – L – type: If you’ve known
printfformatting thoroughly, or formatting on some other languages, it’s easy for you to understand formatting in C++
- fill, align, width are used to fill into additional characters to keep a fixed length
- When the format string is invalid, compilation will fail; if the memory is not enough,
std::bad_allocwill be thrown 格式化无效是时候会导致编译错误,实际上是两个过程 parse 和 format;parse 失败导致编译报错,format 失败会抛出异常 std::format只支持编译期可确定的字符串,不能指定用户输入的字符串- Since C++26, you can use
std::runtime_format
- Since C++26, you can use
1 | |
- C++23 reinforces functionality of
std::format, i.e. it can format a rangestd::vector v{1,2,3}will get[1, 2, 3],std::vector<std::vector<int>> v{{1,2},{3,4}}will get[[1, 2], [3, 4]]- For container adaptors (i.e. stack, queue, priority_queue), they don’t provide iterators so it’s hard to print them before; now they also support
std::format - For
std::vector<bool>, the proxy type doesn’t support output before - For
std::pair/std::tuple, you will get(xx, yy, …) - For associative containers, you will get
{xx:yy, aa:bb,…}or{xx, aa}(depending on map/set)
- Of course, you can add format specifier for elements and ranges
s/?s: only valid for range of string, output string/escaped stringm: only valid for range of pair/tuple of size 2, output as{k1: v1, k2: v2, …}(like element of map)n: strip the surrounding wrapper, e.g.[xx, yy]will becomexx, yy(so that you can customize your parentheses)nm: combinenwithm, i.e. output ask1: v1, k2: v2, …
Print function
- By format, C++23 introduces print functions in
<print>std::print(“{}”, v), orstd::println(“{}”, v)to print an additional\n
User-defined format
Resolving format has two phases
- Parsing: the formatter should parse things in the
{}, and record necessary states 对{}内部的东西进行分词 - Formatting: according to the recorded states of parsing, the string is inserted from back
- Parsing: the formatter should parse things in the
Output scoped enumeration name
enum class Color {Red = 0xFF0000, Green = 0x00FF00, Blue = 0x0000FF, White = 0xFFFFFF};- You need to specialize
std::formatter<T>template<> struct std::formatter<Color>模板的特化 - Then just define a
constexpr auto parse(const std::format_parse_context&)- 可以认为里面的参数就是
std::string_view但是不包含std::string_view的所有方法,只能拿到首尾迭代器,如:.begin()或.end() begin到end之间可以是从{:...}中的:到}结束,或者只包含{:}或{}
- 可以认为里面的参数就是
- 假设只需要两个 specifiers,一个是
x(输出颜色的 16 进制),另一个是s(输出枚举的名字)
- You need to specialize
1 | |
After parsing, we need to utilize saved state to fill in string
- You need
auto format(const T&/T, auto &) const {...}, whereTis the object type (Colorhere) - You can user
.out()to get the output iterator, where you need to append new contents; the function should return new iterator
- You need
NOTE
- 为什么比
printf要快- It tries to parse when compiling, and only fill string in runtime
- C and C functions cannot utilize compile-time evaluation
- you can save the context string in the member in parse, and then print it in format to debug, which saves the trouble that you cannot output in parse
- the general parameter is in fact
std::basic_format_context<T>/std::basic_format_parse_context<T>, which can also support e.g.std::wstring; if you want that,auto&andconst auto&as parameter types are also OK - it’s also acceptable to inherit or own another
std::formatter<T>as member, so that you can utilize its parsing or formatting - C++23 also adds
std::range_formatter<T>, which is used to be inherited bystd::formatter<Container<T>>for customizing range ofTto output 辅助range的格式化
- 为什么比
Stream
Stream is a high-level abstraction of readable/writeable buffer; No matter it’s in fact console, file or memory, users usually don’t need to care about the details, but just see it as a continuous buffer to read/write
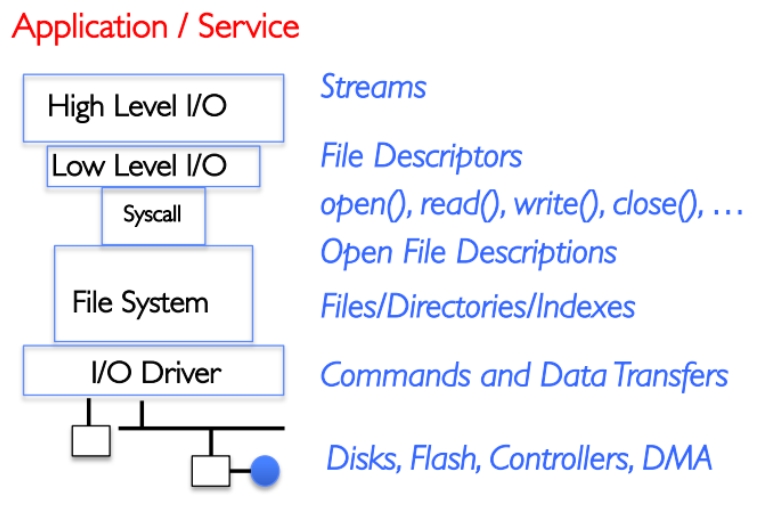
- system call 是非常耗时的
- 准备一个缓冲区,将文件中的大部分内容放到缓冲区里,在缓冲区中通过调整指针读取缓冲区的内容
- 对于写操作,也需要先准备往缓冲区中写入,再 flush 进磁盘中
“Flush to disk” may be not rigorous because it depends on OS; That is, flush in our application level may still be cached in the OS buffer, which needs OS-dependent API to go to disk thoroughly
std::endl v.s. \n
std::endlis in fact a special IO manipulator, meaning that “output a newline, and flush the stream” 立即回显到控制台上- if you output a
\n, file/console may not get it immediately until proper time - 如果一遍一遍的使用
std::endl会很慢,推荐使用\n,必要的时候也可以使用std::flush
Overview
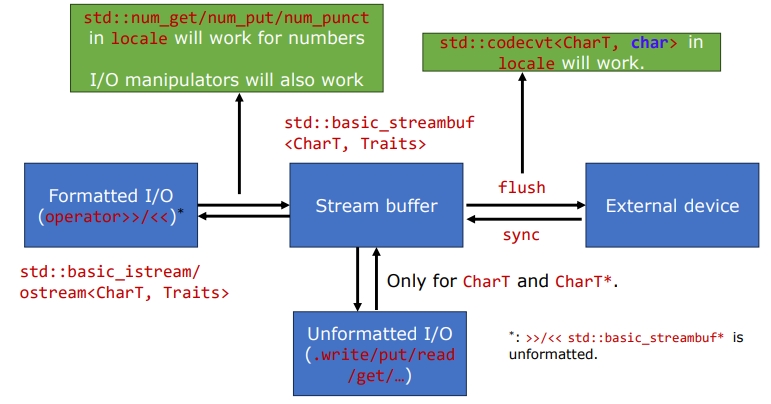
Output stream
- Output stream is inherited from
std::basic_stream - It’s in fact a template, i.e.
<Char, CharTraits = std::char_traits<Char>> - Formatted output: just use
<<(sometimes named “insertion operator”), like what you’ve done instd::cout- Only for raw character (& its array) output; return reference to
*this .put(ch)and.write(chArr, len)- For example,
.write(fmtStr.data(), fmtStr.size())is same as<< fmtStrwith no manipulator
- Only for raw character (& its array) output; return reference to
- Sometimes, you may want to jump to other positions (as if you move the pointer to some place of the whole buffer) 随机读取或者写入
- You can use
.tellp()and.seekp()to get or set the “put” position .tellp()returns &.seekp()acceptsstd::basic_ostream<xx>::pos_type, which can be seen as a signed integer (in fact a classstd::streampos)- Besides, you can use relative position to seek, i.e. by
.seekp(off_type off, std::ios_base::seekdir dir)
- You can use
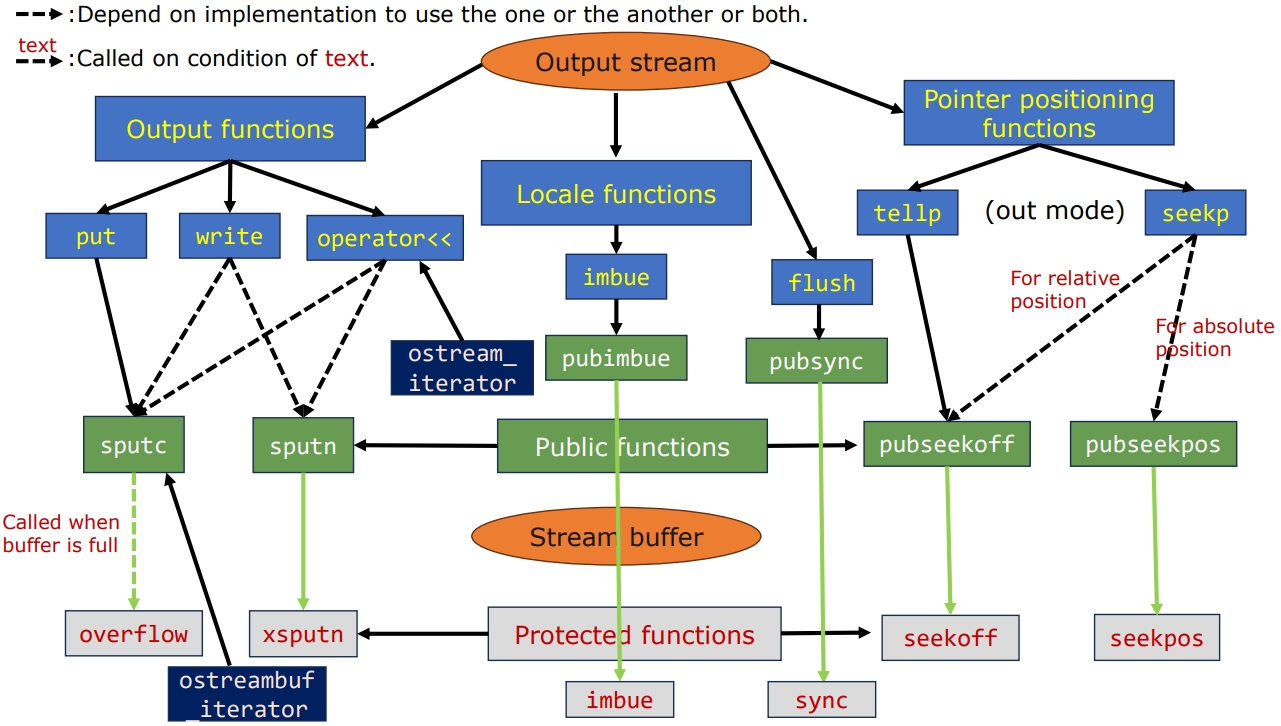
std::basic_streambufalso handles buffering automatically, so derived class doesn’t need to care “when buffer is full”- Usually the derived class has a default memory buffer, while users can use
.pubsetbuf()to set it by themselves - The buffer is abstracted as three components: begin, curr, end
- If you want to adjust
pptrmanually, you can use.pbump(int off)
- Usually the derived class has a default memory buffer, while users can use

- The stream buffer can be got by
.rdbuf(), which returnsstd::basic_streambuf*.pbase()/.pptr()/.epptr(): returnbegin/cur/endpointer.setp(pBeg, pEnd): set the begin/cur/end pointer topBeg/pBeg/pEnd.pbump(int off):cur += off;curcan go out of[begin, end).overflow(int_type ch = Traits::eof()): ifchiseof, then do nothing; otherwise put thechto the proper positioneof– end of file.xsputn(const Char* arr, std::streamsize cnt): output a string to the proper position 把一个字符串输出到合适的位置
- For both input and output buffer, some protected positioning can be overridden
.seekoff(off_type off, seekdir, std::ios_base::openmode mode): seek position by relative offset; the buffer should adjust its pointers to proper position; return the absolute position of typepos_type, orpos_type(-1)if fail 通过相对的位置进行 seek,模式由mode决定.seekpos(pos_type pos, openmode mode): seek position by absolute offset; the buffer should adjust its pointers to proper position; return the absolute position of typepos_type, orpos_type(-1)if fail.sync(): write buffer back for output stream and empty the buffer for input stream. Exposed by.pubsync().setbuf(Char* s, std::streamsize n): allow to set the underlying buffer manually; you can use it to set a larger buffer. Returnthis. Exposed by.pubsetbuf()
Input stream
- Input stream is inherited from
std::basic_istream - Formatted input: just use
>>(sometimes named “extraction operator”), like what you’ve done instd::cin - Unformatted input: not affected by io manipulator
.get(),.get(ch)and.read(chArr, len).get()will returnint_type, while.get(Char& c)will save the result intoc接受引用- For
.read(chArr, len), remaining characters can be less thanlen - You can you
.tellg()and.seekg()to get or set the “get” position
- Beyond these, input stream provides more utility functions
- You can you
.tellg()and.seekg()to get or set the “get” position - Beyond these, input stream provides more utility functions
>> streambuf(only this>>is unformatted) 可以输入到streambuf中.get(Char* buffer, std::streamsize count, delim = Char(‘\n’)): input to the buffer, untildelimor character numbers are count 遇到分割符就停止.getline(Char* buffer, std::streamsize count, delim = Char(‘\n’)): similar to.get, except that it will eat thedelimwhile.get()will keep it in the stream (so that the next time you can still get thedelim).readsome(Char* buffer, std::streamsize count): extract at most count characters from buffer in memory (i.e. no need to reload from e.g. file).ignore(count = 1, delim = Traits::eof()): eat at most count characters / until reachingdelim忽略一些字符,流会“吞掉”一些字符.peek(): get the next character without really changing the status of the stream (i.e. next.get()will get the peeked result). Returneofif stream reaches its end “窥视”下一个字符.unget(): try to put back the last extracted character;.peek()is basically equivalent to.get()+.unget()把上一个字符放回去.putback(ch): try to put an arbitrary character back to the stream.gcount(): get number of characters got from the last unformatted input functions.sync(): synchronize the buffer with the underlying sequence; for example, if the file is written, input stream can use this method to reload
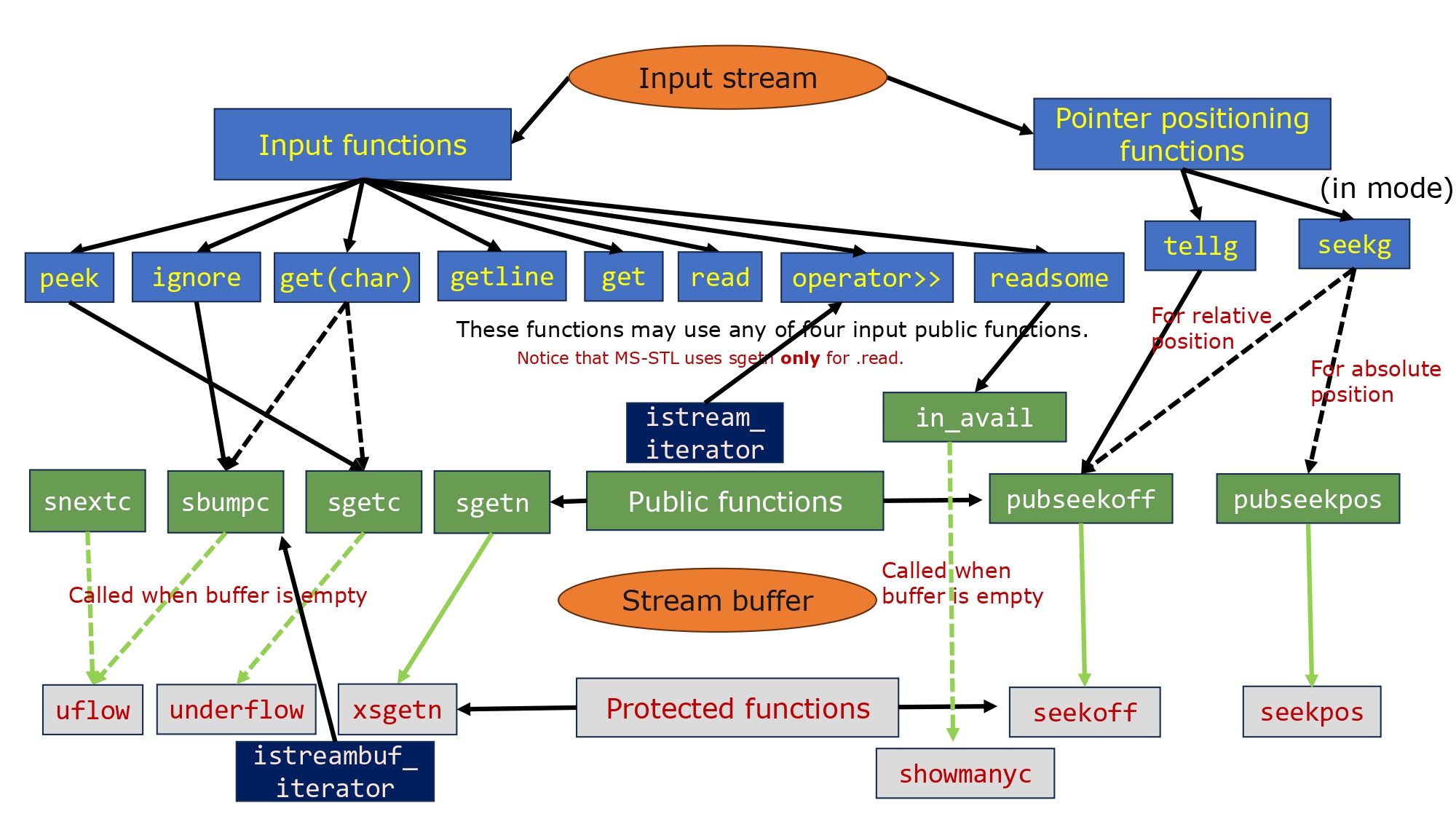
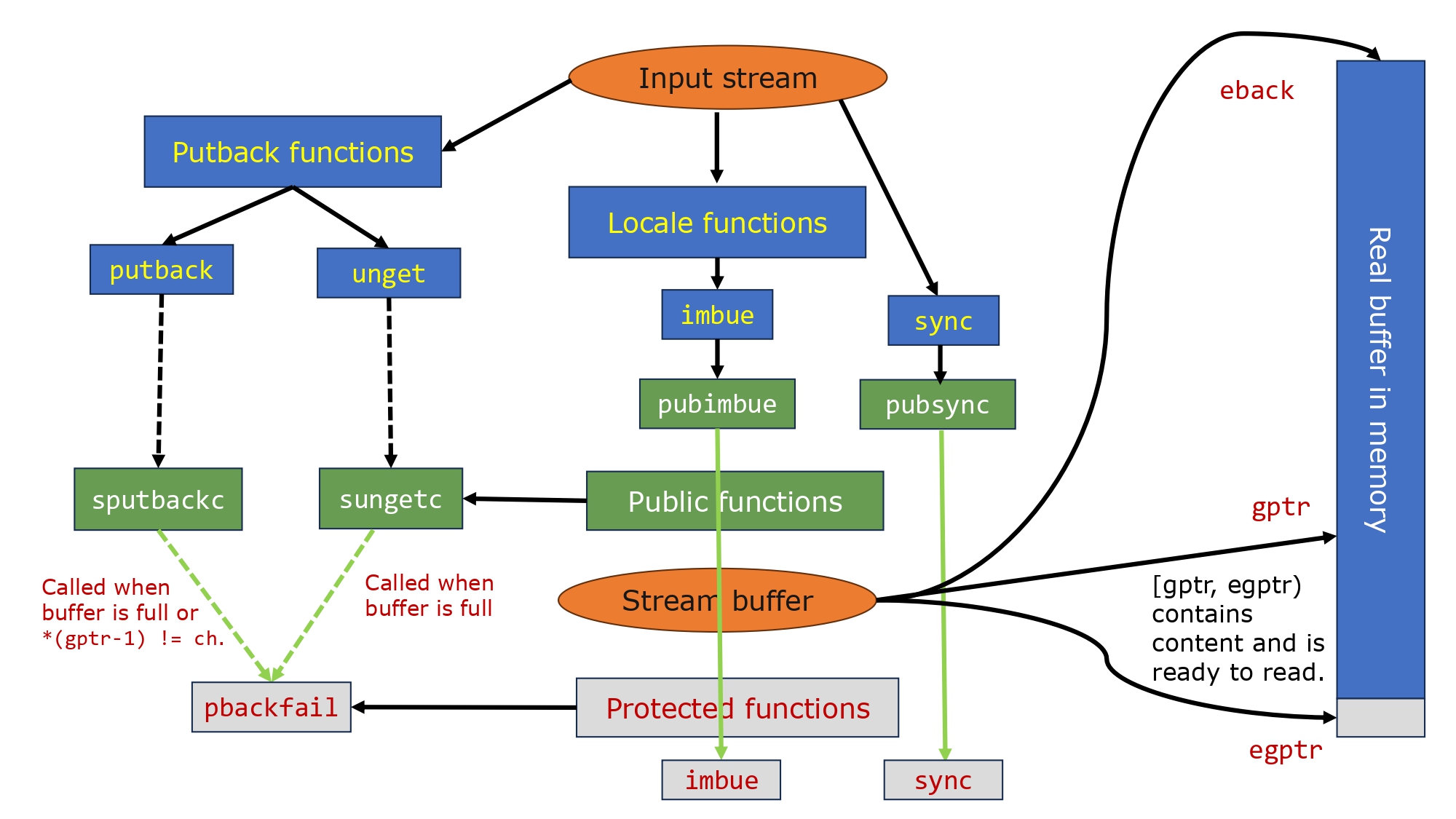
.eback()/.gptr()/.egptr(): returnbegin/cur/endpointer.setg(gBeg, gCurr, gEnd): set thebegin/cur/endpointer togBeg/gCurr/gEnd.gbump(int off):cur += off;curcan go out of[begin, end).underflow(): return the next character and adjust pointers to the proper position. Returneofif fail.uflow():.underflow()and then advance cur by 1.xsgetn(Char* arr, std::streamsize cnt): input a string toarrand return the number of characters that are written successfully.pbackfail(int_type ch = Traits::eof()): this method is called ifeback == gptrorgptr == nullptr or *(gptr–1) != ch(i.e. fail to go back); buffer should put the character back (e.g. for file buffer, it may need to reload buffer by going backwards). Returneofif fail.showmanyc(): abbr. for stream-how-many-character; return estimated remaining number of characters of the underlying sequence (or 0 if not sure; default of base class).showmanyc– string how many characters- If we implement a
TCP_streambufourselves, and we want to know how many characters can be got from the system buffer immediately. Then you can call system API to know it, and returned by.showmanyc
- If we implement a
Stream status
Stream buffer 的 API 好多都返回 eof 表示失败,失败的原因各种各样,需要类型去表示失败的原因,即 Stream status. There are three bits for that: eofbit, failbit and badbit
std::ios_base::eofbitis commonly used to denote end of streamstd::ios_base::failbit: commonly used when parsing error, e.g. if youcin >> SomeFloatbut input a charactera; or failing to open/close filestd::ios_base::badbit: some irrecoverable error happens- You can use
.rdstate()to get the state flags, and test it by e.g.s & eofbit,.clear(states = goodbit)to set flags,.setstate(states)to add flags (equivalent to.clear(rdstate() | states))
However, it’s usually not convenient to operate on bits, so methods are also provided directly
.good()/operator bool: return whether the stream is good.eof(): return whethereofbitis set.fail(): return whetherfailbitorbadbitis set.bad(): return whetherbadbitis set
If you want to throw std::ios_base::failure (derived from std::system_error/runtime_error) when error states occur, you can use .exceptions(states)
When the stream is not good, any input/output will do nothing; so don’t forget to .clear() if you want to continue to use the stream normally
Bidirectional stream
Streams can also both input and output by std::basic_iostream
- It has a single buffer in the
streambuf, with two sets ofbegin/cur/endpointers - It has all methods from
istreamandostream, e.g..tellg/seekg/tellp/seekp() - Whether they share the same position is determined by the derived class. For example, file stream share while other streams don’t
1 | |
Standard streams
There are three pre-defined standard streams with their buffers, inherited from std::basic_istream/ostream/iostream/streambuf
- File stream:
std::basic_ifstream/ofstream/fstreamwithstd::basic_filebufas buffer. They’re defined in<fstream> - String stream:
std::basic_istringstream/ostringstream/stringstream, withstd::basic_stringbufas buffer. They’re defined in<sstream> - Span stream (C++23):
std::basic_ispanstream/ospanstream/spanstream, withstd::basic_spanbufas buffer. They’re defined in<spanstream>
Synchronized output stream: C++20,
std::basic_osyncstream, withstd::basic_syncbufas buffer. They’re defined in<syncstream>
File stream
- Thus, to construct a new file stream, you need a path and open mode 需要一个路径和一个打开方式
- Open mode is widely used in many languages and platform APIs, e.g. C, Python, Go, etc., with slight difference on name or functionality 打开方式在不同语言不同平台下都差不多
in: 只读的方式out: 只写的方式,如果文件不存在就创建;如果文件存在则把整个文件 truncate(从头到尾清空掉)ate: after opening the file, seek the pointer to the end of file immediatelyapp: seek the pointer to the end of file every time before writing happens 每次写之前都把指针调到最后,ate不会调整指针binary: files can be opened in text mode (default) or binary mode- For example, in Windows, newline will output
\r\n(CRLF) though you only write a\n在 Windows 上换行是两个字符表示的\r\n,就算写了\n也会翻译成\r\n,在 Linux 上没有这个问题;用binary就不会出现这种情况 - ATTENTION: This is the only difference between binary mode and text mode
- In binary mode, you can also use
operator<<(e.g.fout << 1). Parameters are formatted to string and the characters are then written 都会被转换为字符串,然后再写到二进制文件中 - There are many files that should be read as pure byte sequence, like some compressed file, video/image, etc
- Similarly, you can use
.read()to read bytes directly
- For example, in Windows, newline will output
- Open mode is widely used in many languages and platform APIs, e.g. C, Python, Go, etc., with slight difference on name or functionality 打开方式在不同语言不同平台下都差不多
Codecvt
- The conversion happens when goes to external device, i.e. the encoding of the memory buffer haven’t changed at all
- Codecvt in file stream is always
std::codecvt<CharT, char>, i.e. convert to char when writing - Notice that MS-STL will cancel codecvt when
.pubsetbuf(CharT*, size), but libc++/libstdc++ won’t - Binary mode for file stream will still go through codecvt
String stream
- The underlying sequence of the string stream is just memory
- The string stream will reallocate when overflow 扩容和
std::string机制一样
Span stream
- String stream will always create a new underlying string, span stream not String stream 会拷贝一份传入进来的字串,创建新的字串;Span stream 提供了一个 buffer,写入溢出后就不能再写入了,Span stream 接受的是一个 buffer,自己并不会拥有这块 buffer
- Changes are applied on the buffer directly, without worrying about whether the output exceeds the buffer (just truncates it rather than reallocate)
- Ctor: use a
span<CharT>+ mode - Get view: .span(), get
span<CharT>(instead ofbasic_string_view<CharT>!)
Synchronized stream
- If you’ve coded some multi-threading program that uses
std::cout, you may find output is messed up…- E.g.
std::cout << “a=” << a << “c=” << c;in two threads may have any permutation (e.g.a=a=1c=c=22)
- E.g.
- Other streams, like file stream you create, will still cause data race because two threads may operate on file pointer simultaneously. You need to add a lock manually
- You need to create two
std::osyncstreamand each thread has its own
IO manipulator
- The vexing fact of IO format manipulators is that many of them will keep the manipulation state so that any following output will be affected
- For those three that have multiple options, their default values are left/dec/fixed
- Fill-align-width-type
- Locale-related manipulators
Regular expression
Regex syntax
- For classic regex, it can be converted to a finite automata (FA, 有限自动机), which will be strictly
- 编译原理会涉及到一些 classic regex
- KMP is a kind of FA in essence
- classic regex 有一些受限
- Its syntax is restricted, which still can only do simple work 经典的正则表达式可以覆盖大部分的词法分析工作
- The FA may be very huge, and its construction also typically needs
(and worst , where is length of regex), which consumes a lot of space and time too 构建有限自动机的时间复杂度就会很高了
- Backtracking 基于回溯的正则表达式引擎
- its time complexity can be as bad as
(or even higher, even never ends!)
- its time complexity can be as bad as
Regex
- Classic regex has these syntax
- Alternative (or):
|; for example,a | bwill match bothaandb - Concatenate: e.g.
awill matcha,bwill matchb→abwill matchab - Kleene closure:
*, which means match more than zero times, e.g.a*will match(i.e. nothing), a,aa,,aaa, … - Precedence of these three operators are
*> concatenate >|, e.g.ab*means e.g.abbbbb… - Combine:
(), which will raise the precedence of some group, e.g.(ab)*
- Alternative (or):
- There are some syntax sugar for it
- Positive closure:
+, which match more than one times - Zero or one:
?, which match zero or one time - Multiple:
a{1,3}will match 1 to 3 times;a{3,}will match at least 3 times - Character class:
[atyz]meansa|t|y|z;[^atyz]means all characters except fora|t|y|z;[a-z]can representa|b|…|z
- Positive closure:
- Beyond these extensions, there are some pre-defined regular definitions
\d: all digits, equivalent to[0-9]\w: all English letters, digits and underscore, i.e.[a-zA-Z0-9_]\s: all blank letters, i.e. whitespace, tab and\n\D,\W,\S:[^0-9],[^a-zA-Z0-9_], all non-blank letters.(yes, a dot): any character
Of course, you need escaped \ to express the original one; considering that C-string needs escaped themselves, you need \\\\ is actually \\, which express \ in regex
- Thus, raw string is extremely important for regex; you need
R"(\\)"for that - Particularly, slash needs escape too, i.e. you need
R"(\/)" - For non-printable values, octal form
\0and hexa form\x…can be used
- Backtracking regex distorts the original semantic meaning of classic regex
- It will not create a FA (thus space consumption and preparation time may be less), so new rules are needed to regulate how to match 基于回溯的正则表达式并不会创建一个有限自动机
- It introduces “greedy match” and “lazy match” 贪婪和懒惰
- That is,
*,+,?will first try to match as much as it can, and*?,+?,??will first try to match as little as it can 基于有限状态机的正则表达式匹配,尽可能的匹配一直到不能匹配为止 - For example,
a+.+to matchaaa,thena+matches all things and.+matches nothing 后面的.+就不匹配了 - And for
a+?.+to matchaaa, thena+?matches only a singleaand.+matchesaa
- That is,
- If the choice doesn’t successfully match, it will go back to the last successful state and try another option (same as DFS) 一种状态下并没有成功匹配,回退到上一个成功的状态,类似 DFS,本质上就是深度有限搜索的过程
- It also extends the functionality of regex
- Anchors 三种锚点
^means matched string must at the beginning 从头开始匹配$means it must go until the end 必须匹配到最后\bmeans ending at word boundary (i.e. the next character after the matched string shouldn’t be\w), and\Bconversely 必须在单词边界停止
- Capture:
()is additionally used to capture matched part, and you can get these capture afterwards 而外的匹配其中的一部分- id is determined by the order of left brace
- The whole matched string is also usually seen as capture 0
- If you don’t want to capture (which will boost performance), use
(?:)instead
- Back reference (not supported by Re2): utilize the captured group in the regex by
\id; e.g.(a+)b\1will match ``aabaain aabaaa, because aa is captured and\1refers to the same thing as it - Look-ahead and look-behind 先行断言和后行断言,统称零宽断言
- Anchors 三种锚点
C++ support for Regex
There are three operations for regex
- Match: match the whole string
- Search: find matched substring
- Replace: replace the matched string with another string
C++ standard library on regex has a tragic performance (even much slower than Python), and doesn’t support Unicode regex
There are some fast alternative solutions
- Boost.Regex, also supports Unicode regex
- CTRE (compile-time regex), which compiles the regex pattern in C++ compilation time and optimizes the matching procedures
- 如果匹配的字串非常长,编译的时间也会变长
- 由于是编译期间确定,所以传入进去的字符串必须是编译期间能确定的
- 不支持 replace
- RE2 by Google, guarantees linear complexity 保证线性时间复杂度,但是不能支持一些复杂度的匹配
- Hyperscan by Intel (only usable on x86/x86-64 Intel platform)
| CTRE | RE2 | |
|---|---|---|
| Parameter | CTRE returns matched result by a struct |
while RE2 by passing pointers |
| Matching | ctre::match<regex>(str) |
bool re2::RE2::FullMatch(str, regex, manyCapturesAddress…) |
| Search | ctre::search<regex>(str) |
bool re2::RE2::PartialMatch(str, regex, manyCapturesAddress…) |
| Replace | bool re2::RE2::Replace(std::string*, regex, replaceStr)/re2::RE2::GlobalReplace(std::string*, regex, replaceStr) |
Move Semantics Basics
Move Ctor & Assignment
- Move Ctor: just steal resource
- Utilize
std::exchange(x, y): assignytoxand return the originalx
- Utilize
- Move Assignment: stealing the resource & release self resource
- rvalues:
- Temporaries, like return value of the function 临时值
- Those labeled with
std::move被std::move标记的值
- In
Func(std::string&& s), issis rvalue?- 变量
s并不是右值 - It just refers to a rvalue from caller, but in the callee it already becomes lvalue 本身不是右值
- “rvalue reference is not necessarily rvalue” 右值引用不必时右值
- 变量
- In facet, this can be generated automatically by compilers (移动)复制和(移动)赋值构造函数是有编译器自动完成的,而且都是逐成员的实现
- Implicit copy ctor -> member-wise copy ctor
- Implicit copy assignment -> member-wise copy assignment
- Implicit move ctor -> member-wise move ctor
- Implicit move assignment -> member-wise move assigment
- Why is it
std::string&&instead ofconst std::string&&?- 在拷贝的时候是不希望传入进来的对象会有任何改变
- 但是当需要移动的时候,调用移动构造函数的调用者本身就知道需要改变传入进来对象的状态(所有权),并不能有
const,所以const std::string&&几乎没有任何用处
- Is self-move legal? 自移动是否是合法的,取决于自己的实现,标准库中都是合法的
- How to define move ctor & assignment for inheritance?
- 和调用父类拷贝 / 赋值构造函数类似
- 需要额外添加
std::move的标记,继续保持右值的属性
- Should move ctor & assignment throw exceptions?
- 移动的
noexcept是非常重要的,确保资源因为抛出异常,需要做回滚,导致不会触发移动构造的效果 - 只有当明确知道会抛出异常不加
noexcept关键字,否则一定要写上,这样才会对性能有明显提升 - Conclusion: move ctor/assignment should almost always be
noexcept
- 移动的