现代 C++ 核心特性解析
本书是一本 C++ 进阶图书,全书分为 42 章,深入探讨了从 C++ 11 到 C++ 20 引入的核心特性。书中不仅通过大量的实例代码讲解特性的概念和语法,还从编译器的角度分析特性的实现原理
01 新基础类型
整数类型long long
long long至少 表示 64 位的整数long不能比int短,所以可以相等long就是long int,同理long long就是long long int- 初始化可以添加
l或L后缀,long long x = 65536LL; - 可以用于枚举类型或位域
1
2
3
4
5
6
7
8
9
10enum longlong_enum : long long {
x1,
x2
};
struct longlong_struct { // 位域可以用来解析协议
long long x1 : 8,
long long x2 : 24,
long long x3 : 32
}
long long格式化输出可以使用 %lld、%llu,int 格式化输出可以使用 %d,short 格式化输出可以使用%h,应该是 half 的意思
新字符串类型 char16_t 和char32_t
- 分别对应 Unicode 的 UTF-16 和 UTF-32
- UTF-32 编码简单但是占用内存多
- 所有字符都映射
- UTF-16 占用内存少但是不够用
- 常用字符做唯一映射
- 其余字符采用了一种特殊的方法表示 Unicode 字符
- UTF-8 一般序列化到磁盘中,不存在内存中
- 变长编码
- 查找和获取大小比较麻烦
wchar_t存在的问题- 在 Windows 上
wchat_t是 16 位,而在 Linux 和 macOS 上wchat_t是 32 位的 - 无法保证相同的代码在不同平台上有相同的行为
char16_t和char32_t解决了这个问题
- 在 Windows 上
char8_t字符类型 C++ 20- 使用
char类型来处理 UTF-8 字符虽然可行,但是也会带来一些困扰,比如当库函数需要同时处理多种字符时必须采用不同的函数名称,以区分普通字符和 UTF-8 字符 char8_t可以代替char作为 UTF-8 的字符类型
- 使用
02 内联和嵌套命名空间
C++11 标准增强了命名空间的特性,提出了内联命名空间的概念。内联命名空间能够把空间内函数和类型导出到父命名空间中,这样即使不指定子命名空间也可以使用其空间内的函数和类型了
1 | |
嵌套命名空间的简化语法 C++ 17
1
2
3namespace A::B::C {
int foo () { return 5; }
}内联命名空间 C++ 20
1
2
3
4
5
6
7namespace A::B::inline C {
int foo () { return 5; }
}
// 或者
namespace A::inline B::C {
int foo () { return 5; }
}
03 auto占位符
C++ 98 开始就有了,平常定义的变量都是
auto的,也可以不写C++ 11 开始赋予了新的含义
声明多个变量时,从左往右推导,必须一致
条件表达式推导出更强的类型 e.g.
auto i = true ? 5 : 8.8i的类型为double初始化静态成员变量必须加
constC++ 111
2
3struct sometype {
static const auto i = 5;
}C++ 17 标准中,
auto可以在没有const的情况下使用 C++ 171
2
3struct sometype {
static inline auto i = 5;
}
C++ 20 之前,无法在函数形参列表中使用
auto声明形参 e.g.void echo(auto str) { ... }auto可以为 lambda 表达式声明形参 C++ 14
如果
auto声明的变量时按值初始化,则推导出的类型会忽略 cv 限定符1
2
3
4
5const int i = 5;
auto j = i; // auto 推导类型为 int,而非 const int
auto &m = i; // auto 推导类型为 const int,m 推导类型为 const int&
auto *k = &i; // auto 推导类型为 const int,k 推导类型为 const int*
const auto n = j; // auto 推导类型为 int,n 的类型为 const int- 对于值类型的推导只是值上的关系,没有内存的关联
- 但是对于引用或指针涉及到了内存的关联,需要保留 cv 限定符
使用
auto声明变量初始化时,目标对象如果是引用,则引用属性会被忽略1
2
3int i = 5;
int &j = i;
auto m = j; // auto 推导类型为 int,而非 int&使用
auto和万能引用声明变量时,对于左值会将auto推导为应用类型1
2
3int i = 5;
auto&& m = i; // auto 推导类型为 int&,这里涉及引用折叠的概念(遇左则左)
auto&& j = 5; // auto 推导类型为 int使用
auto声明变量,如果对象目标是一个数组或者函数,则auto会被推导为对应的指针类型当
auto关键字与列表初始化组合时 C++ 17- 直接使用列表初始化,列表中必须为单元素,否则无法编译,
auto类型被推导为单元素的类型 - 用等号加初始化列表,列表中可以包含单个或多个元素,
auto类型别推导为std::initializer_list<T>,其中T是元素类型
1
2
3
4
5auto x1 = { 1, 2 }; // x1 类型为 std::initializer_list<int>
auto x2 = { 1, 2.0 }; // 编译失败,花括号中元素类型不同
auto x3{ 1, 2 }; // 编译失败,不是单个元素
auto x4 = { 3 }; // x4 类型为 std::initializer_list<int>
auto x5{ 3 }; // x5 类型为 int- 直接使用列表初始化,列表中必须为单元素,否则无法编译,
1 | |
由于 auto b = *d; 是按值赋值的,因此 auto 会直接推导为 Base。代码自然会调用Base 的复制构造函数,也就是说 Derived 被切割(Sliced)成了 Base,如果是auto &b1 = *d 或者 auto *b2 = d 则会触发多态的性质
返回类型声明为
auto的推导 e.g.auto sum(int a, int b) { return a + b; }C++ 14如果有多重返回值,那么需要保证返回值类型是相同的,否则会编译失败
1
2
3
4
5
6
7
8auto sum(long a, long b) {
if (a < 0) {
return 0; // 返回 int 类型
}
else {
return a + b; // 返回 long 类型
}
}
可以把
auto写到 lambda 表达式的形参中,这样就得到了一个泛型的 lambda 表达式 C++ 14非类型模板形参占位符 C++ 17
1
2
3
4
5
6
7
8
9
10#include <iostream>
template<auto N>
void f() {
std::cout << N << std::endl;
}
int main() {
f<5>(); // N 为 int 类型
f<'c'>(); // N 为 char 类型
f<5.0>(); // 编译失败,模板参数不能为 double
}
04 decltype说明符
- 使用
decltype说明符可以获取对象或者表达式的类型,其语法与typeof类似 C++ 11
1 | |
C++ 11 标准中,auto作为占位符不能是编译器对函数返回类型进行推导,必须使用返回类型后置的形式指定返回类型,如果想泛化这个函数,需要使用到函数模板
1 | |
但是如果传递不同类型的实参,则无法编译通过 e.g. auto x2 = sum(5, 10.5);,只能增加模板类型来解决了
1 | |
这时可以使用 decltype 进行优化 C++ 11
1 | |
decltype(a1 + a2)的作用域是这个函数,也就是说表达式里面的变量必须是在函数中的形参- 编译阶段进行推导
C++ 14 标准已经支持对 auto 声明的返回类型进行推导了 C++ 14
1 | |
auto作为返回类型的占位符还存在一些问题
1 | |
这里 auto 被推导为值类型,参考 auto 占位符规则,如果想正确地返回引用类型,则需要使用 decltype 说明符
1 | |
推导规则
decltype(e),e的类型为T- 如果
e是一个未加括号的标识符表达式(结构化绑定除外)或者未加括号的类成员访问,则decltype(e)推断出的类型是e的类型T。如果并不存在这样的类型,或者e是一组重载函数,则无法进行推导 没有候选或者候选太多- 如果加上括号则推断出的是引用类型
- 如果
e是一个函数调用或者仿函数调用,那么decltype(e)推断出的类型是其返回值的类型 - 如果
e是一个类型为T的左值,则decltype(e)是T& - 如果
e是一个类型为T的将亡值,则decltype(e)是T&& - 除去以上情况,则
decltype(e)是T
- 如果
cv 限定符的推导
通常情况下,
decltype(e)所推导的类型会同步e的 cv 限定符当
e是未加括号的成员变量时,父对象表达式的 cv 限定符会被忽略,不能同步推导结果,只有加括号时 cv 限定符会同步到推断结果1
2
3
4
5struct A {
double x;
}
const A* a = new A();
decltype(a->x); // decltype(a->x) 推导类型为 double,const 属性被忽略
decltype(auto)C++ 14- 告诉编译器用
decltype推导表达式规则来推导auto decltype(auto)必须单独声明,不能结合指针、引用以及 cv 限定符
1
2
3
4
5
6
7
8
9
10
11
12int i;
int&& f();
auto x1a = i; // x1a 推导类型为 int
decltype(auto) x1d = i; // x1d 推导类型为 int
auto x2a = (i); // x2a 推导类型为 int
decltype(auto) x2d = (i); // x2d 推导类型为 int&
auto x3a = f(); // x3a 推导类型为 int
decltype(auto) x3d = f(); // x3d 推导类型为 int&&
auto x4a = { 1, 2 }; // x 推导类型为 std::initializer_list<int>
decltype(auto) x4d = { 1, 2 }; // 编译失败,{ 1, 2 } 不是表达式
auto *x5a = &i; // x5a 推导类型为 int*
decltype(auto) *x5d = &i; // x 编译失败,decltype(auto) 必须单独声明auto和decltype(auto)的用法几乎相同,只是在推导规则上遵循decltype而已之前代码
return_ref想返回一个引用类型,但是如果直接使用auto,则一定会返回一个值类型,解决方案是采用后置的方式声明返回类型,现在可以通过decltype(auto)也可以解决1
2
3
4
5
6template<class T>
decltype(auto) return_ref(T& t) {
return t;
}
int x1 = 0;
static_assert(std::is_reference_v<decltype(return_ref(x1))>); // 编译成功decltype(auto)作为非理性模板形参占位符
1
2
3
4
5
6
7
8
9
10
11
12
13#include <iostream>
template<decltype(auto) N>
void f() {
std::cout << N << std::endl;
}
static const int x = 11;
static int y = 7;
int main() {
f<x>(); // N 为 const int 类型
f<(x)>(); // N 为 const int& 类型
f<y>(); // 编译失败,因为 y 不是一个常量,编译器无法对函数模板进行实例化
f<(y)>(); // N 为 int& 类型,恰好对于静态对象而言内存地址时固定的,所以可以通过编译
}- 告诉编译器用
05 函数返回类型后置 C++ 11
返回类型比较复杂的是时候,比如返回一个函数指针类型,使用返回类型后置
1
2
3
4
5
6
7
8
9
10
11
12int bar_impl(int x) {
return x;
}
typedef int(*bar)(int);
bar foo1() {
return bar_impl;
}
auto foo2() -> int (*)(int) {
return bar_impl;
}有了返回类型后置,返回类型就可以用
auto占位符,再后置函数指针类型,不需要写typedef推导函数模板返回类型
06 右值引用
左值和右值
i++:先把i的值取出来存到临时变量中,再把i加一,最后返回的是临时变量的值,属于右值(将亡值)++i:自增后将自己返回,属于左值- 但凡能取地址
&,就是左值 - 通常字面量都是一个右值,除了字符串字面量以外
- 字符串是一块连续的内存,通常存在静态数据去里面
左值引用
- 指针最危险的地方在于可以运算
- C++ 是弱类型语言,类型之前可以随意转换
1 | |
- 非常量左值的引用对象必须是一个左值
- 引用一块内存首先要有一块内存,如果引用右值,内存都不知道在哪,肯定就有问题了
- 常量左值引用的对象可以是左值,也可以是右值
- 在函数形参列表中有着很大的作用
1 | |
- 如果将类
X的复制构造函数和复制赋值构造函数形参类型的常量性删除,则X x3(make_X());和x3 = make_X();会报错,因为非常量左值引用无法绑定到右值上 - 缺点是一旦使用了常量左值应用,就无法在函数内部修改该对象的内容
1 | |
C++ 17 之后编译器有做拷贝优化,虽然返回值是右值,函数返回类型是左值,因为做了拷贝优化所以不会报错
右值引用
- 右值引用可以延长右值的声明周期
- 右值引用可以减少对象复制,提升程序性能
1 | |
- 调用复制构造函数会严重影响运行性能
- 对于复制构造函数而言形参是一个左值引用,函数的实参必须是一个具名的左值,不能破坏实参对象的前提下复制目标对象
- 移动构造函数接受的是一个右值,通过转移实参对象的数据以达成构造目标对象的目的,也就是说实参对象是会被修改的
- 传过来的参数用过之后就没有用了
- 编译器生成的移动构造函数和复制构造函数并没有什么区别
- 编写移动语义的函数时建议确保函数不会抛出异常
- 如果无法保证移动构造函数不会抛出异常,可以使用
noexcept说明符限制该函数。这样当函数抛出异常的时候,程序不会再继续执行而是调用std::terminate中止执行
值类别
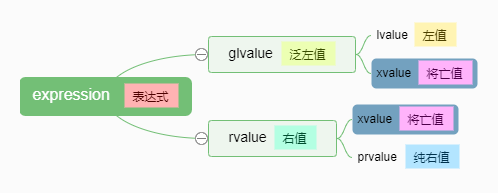
左值和右值实际上指的是表达式,表达式的结果就是值
将亡值产生
使用类型转换将泛左值转换为该类型的右值引用
临时量实质化 C++ 17
1
2
3
4
5
6
7struct X {
int a;
};
int main() {
int b = X().a;
}- 纯右值转换到临时对象的过程
- 每当纯右值出现在一个需要泛左值的地方时,临时量实质化都会发生——创建一个临时对象并且使用纯右值对其进行初始化
- 只要返回的是纯右值就不会调用类的构造函数了
在 C++11 标准中可以在不创建临时值的情况下显式地将左值通过
static_cast转换为将亡值1
2int i = 0;
int &&k = static_cast<int&&>(i);这个转换既不改变生命周期也不改变内存地址,最大作用是让左值使用移动语义
正确的使用场景是在一个右值被转换为左值后需要再次转换为右值
1 | |
- 无论一个函数的实参是左值还是右值,其形参都是一个左值,即使这个形参看上去是一个右值引用
BigMemoryPool my_pool(pool);还是会调用复制构造函数而非移动构造函数BigMemoryPool my_pool(static_cast<BigMemoryPool&&>(pool));则会调用移动构造函数进行构造- 在 C++ 11 的标准库中还提供了一个函数模板
std::move将左值转换为右值 e.g.BigMemoryPool my_pool(std::move(pool));
万能引用和引用折叠
1 | |
&&i就是定义出来具体的参数,字面意思- 而模板有实例化的过程,所以就是万能引用
- 所谓的万能引用就是发生类型推导
| 模板类型 | T实际类型 |
最终类型 |
|---|---|---|
T& |
R |
R& |
T& |
R& |
R& |
T& |
R&& |
R& |
T&& |
R |
R&& |
T&& |
R& |
R& |
“遇左则左”
- 只要有左值引用参与进来,最后推导的结果就是一个左值引用
- 只有实际类型是一个非引用类型或者右值引用类型时,最后推导出来的才是一个右值引用
1 | |
normal_forwarding(get_string());因为normal_forwarding接受的是左值,而传入的是右值可以将
void normal_forwarding(T &t)替换为void normal_forwarding (const T &t)来解决这个问题- 常量左值引用是可以引用右值的
- 但是不能修改传入进来的数据了
可以用引用折叠规则来处理
1
2
3
4
5template<class T>
void perfect_forwarding(T &&t)
{
show_type(static_cast<T&&>(t));
}在 C++ 11 的标准库中提供了一个
std::forward函数模板,在函数内部也是使用static_cast进行类型转换
remove_reference移除引用,根据不同的类型去匹配
1 | |
std::forward
1 | |
std::move
1 | |
针对局部变量和右值引用的隐式移动操作
1 | |
-fno-elide-constructors选项用于关闭返回值优化,才会出现三次输出
- 如果没有移动构造函数,则会调用三次复制构造函数
- 如果定义了移动构造函数,会隐式地采用移动构造函数,调用三次移动构造函数
- 隐式移动操作针对右值引用和
throw的情况进行了扩展 C++ 20 - 可隐式移动的对象必须是一个非易失或一个右值引用的非易失自动存储对象,在以下情况下可以使用移动代替复制
return或者co_return语句中的返回对象是函数或者 lambda 表达式中的对象或形参throw 语句中抛出的对象是函数或try代码块中的对象
小结
对于这些优化空间,C++ 委员会已经对标准库进行了优化,比如常用的容器 vector、list 和map等均已支持移动构造函数和移动赋值运算符函数。另外,如 make_pair、make_tuple 以及 make_shared 等也都使用完美转发以提高程序的性能
07 lambda 表达式
语法定义:[captures](params) specifiers exception -> ret {body}
[captures]在大部分其他语言是不存在的,因为诸如 Java、C# 等语言是有 GC 机制的,不需要担心捕获对象的声明周期的问题[captures]—— 捕获列表,它可以捕获当前函数作用域的零个或多个变量,变量之间用逗号分隔。捕获列表的捕获方式有两种:按值捕获和引用捕获(params)—— 可选参数列表,语法和普通函数的参数列表一样,在不需要参数的时候可以忽略参数列表specifiers—— 可选限定符,C++11 中可以用mutable,它允许在 lambda 表达式函数体内改变按值捕获的变量,或者调用非const的成员函数exception—— 可选异常说明符,可以使用noexcept来指明 lambda 是否会抛出异常-> ret—— 可选返回值类型,不同于普通函数,lambda 表达式使用返回类型后置的语法来表示返回类型,如果没有返回值(void类型),可以忽略包括->在内的整个部分{ body }—— lambda 表达式的函数体,这个部分和普通函数的函数体一样
不允许捕获全局变量和静态变量,因为可以直接使用
lambda 表达式按值捕获每次调用都会保留上一次修改的值,具体参考 lambda 表达式实现原理
特殊的捕获方法
[this]—— 捕获this指针,捕获this指针可以使用this类型的成员变量和函数[=]—— 捕获 lambda 表达式定义作用域的全部变量的值,包括this[&]—— 捕获 lambda 表达式定义作用域的全部变量的引用,包括this
lambda 表达式的优势在于书写简单方便且易于维护
函数对象的优势在于使用更加灵活不受限制
lambda 表达式实现原理
1
2
3
4
5
6
7#include <iostream>
int main()
{
int x = 5, y = 8;
auto foo = [=] { return x * y; };
int z = foo();
}用 CppInsights 输出其 GIMPLE 的中间代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#include <iostream>
int main()
{
int x = 5;
int y = 8;
class __lambda_5_16
{
public:
inline /*constexpr */ int operator()() const
{
return x * y;
}
private:
int x;
int y;
public:
__lambda_5_16(int & _x, int & _y): x{_x}, y{_y} {}
};
__lambda_5_16 foo = __lambda_5_16{x, y};
int z = foo.operator()();
return 0;
}- lambda 表达式在编译期会由编译器自动生成一个闭包类,在运行时由这个闭包类产生一个对象,称为闭包。在 C++ 中,所谓的闭包可以简单地理解为一个匿名且可以包含定义时作用域上下文的函数对象
- lambda 表达式是 C++11 提供的一块语法糖而已,lambda 表达式的功能完全能够手动实现,而且如果实现合理,代码在运行效率上也不会有差距,只不过实用 lambda 表达式让代码编写更加轻松了
无状态的 lambda 表达式
有状态会在匿名类中定义按值捕获的变量,从而在每次调用的时候都会保持变量上一次的状态
如果是无状态的 lambda 表达式,可以隐式转换为函数指针
1
2void f(void(*)()) {}
void g() { f([] {}); } // 编译成功尽量让 lambda 表达式“纯粹”一些,不捕获外部变量
在 STL 中使用 lambda 表达式
std::sort、std::find_if
广义捕获 C++ 14
简单捕获
初始化捕获
- 捕获表达式结果
- 自定义捕获变量名
1
2
3
4
5int main() {
int x = 5;
auto foo1 = [x = x + 1] { return x; }; // 两个 x 的作用域不一样
auto foo2 = [r = x + 1] { return r; }; // 推荐的写法
}1
2
3
4
5
6#include <string>
int main()
{
std::string x = "hello c++ ";
auto foo = [x = std::move(x)]{ return x + "world"; };
}- 使用
std::move对捕获列表变量 x 进行初始化,这样避免了简单捕获的复制对象操作
异步调用时复制
this对象,防止 lambda 表达式被调用时因原始this对象被析构造成未定义的行为1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#include <iostream>
#include <future>
class Work {
private:
int value;
public:
Work() : value(42) {}
std::future<int> spawn() {
return std::async([=]() -> int { return value; });
}
};
std::future<int> foo() {
Work tmp;
return tmp.spawn();
}
int main() {
std::future<int> f = foo();
f.wait();
std::cout << "f.get() = " << f.get() << std::endl;
}输出结果
1
f.get() = 32766f.wait()调用之后,访问value这块内存的时候已经是未知的状态解决方法就是可以将对象复制到 lambda 表达式内
1
2
3
4
5
6
7
8
9class Work {
private:
int value;
public:
Work() : value(42) {}
std::future<int> spawn() {
return std::async([=, tmp = *this]() -> int { return tmp.value; });
}
};这种方式也不能解决所有问题,一个技术手段是不能解决所有问题的,需要在合适的场景下提出不同的解决方案
泛型 lambda 表达式 C++ 14
- 定义方式不用
template关键字,只需要使用auto占位符即可
1
2
3
4
5
6int main()
{
auto foo = [](auto a) { return a; };
int three = foo(3);
char const* hello = foo("hello");
}- 定义方式不用
常量 lambda 表达式 C++ 17
捕获
*this增强 C++ 17- 不需要额外定义变量初始化捕获列表,直接使用
*this就是一份拷贝
- 不需要额外定义变量初始化捕获列表,直接使用
捕获
[=, this]C++ 20- 表达的意思和
[=]相同,目的区分它与[=,*this]的不同 - C++ 20 标准中还特别强调了要用
[=, this]代替[=] - 希望捕获
this时,把this写出来
- 表达的意思和
1 | |
普通的函数模板可以轻松地通过形参模式匹配一个实参为
vector的容器对象,但是对于 lambda 表达式,auto不具备这种表达能力,所以不得不实现is_std_vector,并且通过static_assert来辅助判断实参的真实类型是否为vector如果用 lambda 表达式想获取
vector里面的T的类型就会更复杂1
2
3
4auto f = [] (auto vector) {
using T = typename decltype(vector)::value_type;
// ...
}vector容器类型会使用内嵌类型value_type表示存储对象的类型- 不能保证面对的所有容器都会实现这一规则,所以依赖内嵌类型是不可靠的
还有一个问题是
decltype(obj)有时候并不能直接获取想要的类型1
2
3
4
5auto f = [](const auto& x) {
using T = decltype(x);
T copy = x; // 可以编译,但是语义错误
using Iterator = typename T::iterator; // 编译错误
};decltype(x)推导出来的类型并不是std::vector,而是const std::vector &,所以T copy = x;不是一个复制而是引用对于一个引用类型来说,
T::iterator也是不符合语法的,所以编译出错可以将类型的 cv 以及引用属性删除
1
2
3
4
5auto f = [](const auto& x) {
using T = std::decay_t<decltype(x)>;
T copy = x;
using Iterator = typename T::iterator;
};
模板语法的泛型 lambda 表达式 C++ 20
[]<template T>(T t) {}
可构造和可赋值的无状态 lambda 表达式 C++ 20
std::sort和std::find_if这样的函数需要一个函数对象或函数指针来辅助排序和查找,这种情况可以使用 lambda 表达式完成任务std::map的比较函数对象是通过模板参数确定的,这个时候需要的是一个类型1
2auto greater = [](auto x, auto y) { return x > y; };
std::map<std::string, int, decltype(greater)> mymap; // 需要的是类型所以用 `decltype`- 但是在 C++ 17 标准中是不可行的,因为 lambda 表达式类型无法构造,lambda 表达式的默认构造函数已经被删除了
- 无状态的 lambda 表达式也没办法赋值,原因是复制赋值函数被删除了
- 使用 C++ 20 标准的编译环境来编译上面的代码是可行的
08 非静态数据成员默认初始化
声明非静态数据成员的同时直接对其使用
=或者{}初始化 C++ 11在此之前只有类型为整型或者枚举类型的常量静态数据成员才可以这样初始化
初始化列表对数据成员的初始化总是优先于声明时默认初始化
不要使用括号
()对非静态数据成员进行初始化,因为这样会造成解析问题,所以会编译错误不要用
auto来声明和初始化非静态数据成员位域的默认初始化 C++ 20
1
2
3
4struct S {
int y : 8 = 11;
int z : 4 = { 7 };
}int数据的低 8 位被初始化为 11,紧跟它的高 4 位被初始化为 7
09 列表初始化
- 列表初始化,使用大括号
{}对变量进行初始化 C++ 11 - 传统变量初始化的规则一样,它也区分为直接初始化和拷贝初始化
1 | |
std::initializer_list简单地说就是一个支持begin、end以及size成员函数的类模板- 实际上是一块连续的内存,也就是数组
隐式缩窄转换问题
1
2int x = 12345;
char y = x; // 将超过 char 大小的数据赋值给 char,明显是一个隐式缩窄转换- 传统变量初始化中是没有问题的,代码能顺利通过编译
- 如果采用列表初始化,根据标准编译器通常会给出一个错误
- 隐式缩窄转换发生的情况 表示范围大的类型向表示范围小的类型转换就发生了缩窄
- 从浮点类型转换整数类型
- 从
long double转换到double或float,或从double转换到float,除非转换源是常量表达式以及转换后的实际值在目标可以表示的值范围内 - 从整数类型或非强枚举类型转换到浮点类型,除非转换源是常量表达式,转换后的实际值适合目标类型并且能够将生成目标类型的目标值转换回原始类型的原始值
- 从整数类型或非强枚举类型转换到不能代表所有原始类型值的整数类型,除非源是一个常量表达式,其值在转换之后能够适合目标类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20int x = 999;
const int y = 999;
const int z = 99;
const double cdb = 99.9;
double db = 99.9;
char c1 = x; // 编译成功,传统变量初始化支持隐式缩窄转换
char c2{ x }; // 编译失败,可能是隐式缩窄转换,对应规则 4
char c3{ y }; // 编译失败,确定是隐式缩窄转换,999 超出 char 能够适应的范围,对应规则 4
char c4{ z }; // 编译成功,99 在 char 能够适应的范围内,对应规则 4
unsigned char uc1 = { 5 }; // 编译成功,5 在 unsigned char 能够适应的范围内,
// 对应规则 4
unsigned char uc2 = { -1 }; // 编译失败,unsigned char 不能够适应负数,对应规则 4
unsigned int ui1 = { -1 }; // 编译失败,unsigned int 不能够适应负数,对应规则 4
signed int si1 = { (unsigned int)-1 }; // 编译失败,signed int 不能够适应 -1 所对应的
//unsigned int,通常是 4294967295,对应规则 4
int ii = { 2.0 }; // 编译失败,int 不能适应浮点范围,对应规则 1
float f1{ x }; // 编译失败,float 可能无法适应整数或者互相转换,对应规则 3
float f2{ 7 }; // 编译成功,7 能够适应 float,且 float 也能转换回整数 7,对应规则 3
float f3{ cdb }; // 编译成功,99.9 能适应 float,对应规则 2
float f4{ db }; // 编译失败,可能是隐式缩窄转无法表达 double,对应规则 2如果有一个类同时拥有满足列表初始化的构造函数,且其中一个是以
std::initializer_list为参数,那么编译器将优先以std::initializer_list为参数构造函数指定初始化 C++ 20
1
2
3
4
5
6struct Point {
int x;
int y;
int z;
};
Point p{ .x = 4, .y = 2 }; // z = 0并不是什么对象都能够指定初始化
对象必须是一个聚合类型
指定的数据成员必须是非静态数据成员 静态数据成员不属于某个对象
每个非静态数据成员最多只能初始化一次
1
Point p{ .y = 4, .y = 2 }; // 编译失败,y 不能初始化多次非静态数据成员的初始化必须按照声明的顺序进行
- 在 C 语言中,乱序的指定初始化是合法的,但 C++ 不行
- C++ 中的数据成员会按照声明的顺序构造,按照顺序指定初始化会让代码更容易阅读
1
Point p{ .y = 4, .x = 2 }; // C++ 编译失败,C 编译正常针对联合体中的数据成员只能初始化一次,不能同时指定
1
2
3
4
5
6
7union u {
int a;
const char* b;
};
u f = { .a = 1 }; // 编译成功
u g = { .b = "a" }; // 编译成功
u h = { .a = 1, .b = "a" }; // 编译失败,同时指定初始化联合体中的多个数据成员不能嵌套指定初始化数据成员
- C 语言中也是允许的
- C++ 标准认为这个特性很少有用,所以直接禁止了
1
2
3
4
5struct Line {
Point a;
Point b;
};
Line l{ .a.y = 5 }; // 编译失败,.a.y = 5 访问了嵌套成员,不符合 C++ 标准如果确实想嵌套指定初始化,可以换一种形式来达到目的
1
Line l{ .a { .y = 5 } };
一旦使用指定初始化,就不能混用其他方法对数据成员初始化了
1
Point p{ .x = 2, 3 }; // 编译失败,混用数据成员的初始化指定初始化不能初始化数组的某一位置 C++ 标准中给出的禁止理由非常简单,它的语法和 lambda 表达式冲突了
1
int arr[3] = { [1] = 5 }; // 编译失败
10 默认和删除函数
- 在没有自定义构造函数的情况下,编译器会为类添加默认的构造函数
- 默认构造函数
- 析构函数
- 复制构造函数
- 复制赋值运算符函数
- 移动构造函数 C++ 11
- 移动赋值运算符函数 C++ 11
- 添加默认特殊成员函数也会带来一些问题
- 声明任何构造函数都会抑制默认构造函数的添加 显示的定义了非默认构造函数,编译器不再为类提供默认构造函数
- 一旦用自定义构造函数代替默认构造函数,类就将转变为 非平凡类型
- 如果自定义了构造函数(即使是默认构造函数),有可能编译器只能看到声明,看不到实现,就没办法做一些优化处理了
- 平凡类型可以想象为 C 的结构体
- 没有明确的办法彻底禁止特殊成员函数的生成 C++ 11 之前
禁止重载函数的某些版本
1 | |
- 无法通过编译。因为
using说明符无法将基类的私有成员函数引入子类当中 - C++ 11 标准提供了一种方法能够简单有效又精确地控制默认特殊成员函数的添加和删除
- 在声明函数的尾部添加
= default和= delete - 相对于使用
private限制函数访问,使用= delete更加彻底,它从编译层面上抑制了函数的生成,所以无论调用者是什么身份(包括类的成员函数),都无法调用被删除的函数 - 显式删除不仅适用于类的成员函数,对于普通函数同样有效 应用于普通函数的意义就不大了
- 显式删除还可以用于类的
new运算符和类析构函数- 作用于
new运算符可以阻止该类在堆上动态创建对象
- 作用于
- 在类的构造函数上同时使用
explicit和= delete是一个不明智的做法,它常常会造成代码行为混乱难以理解,应尽量避免这样做
11 非受限联合类型
- C++ 中的联合类型(
union)可以说是节约内存的一个典型代表 - 在联合类型中多个对象可以共享一片内存,相应的这片内存也只能由一个对象使用
- 过去的 C++ 标准规定,联合类型的成员变量的类型不能是一个非平凡类型,也就是说它的成员类型不能有自定义构造函数
- 在 C++11 中如果有联合类型中存在非平凡类型,那么这个联合类型的特殊成员函数将被隐式删除,也就是说必须至少提供联合类型的构造和析构函数
1 | |
修改后
1 | |
- 在构造函数中添加了初始化列表来构造
x3,在析构函数中手动调用了x3的析构函数 - 联合类型在析构的时候编译器并不知道当前激活的是哪个成员,所以无法自动调用成员的析构函数
- 但是如果初始化
x4又会出现问题,所以继续修改代码
1 | |
上面的代码用了 placement new 的技巧来初始化构造
x3和x4对象在使用完对象后手动调用对象的析构函数
通过这样的方法保证了联合类型使用的灵活性和正确性
联合类型其实就是 C 语言的遗产
可以使用
std::variant来代替联合类型 C++ 17- 是 类型安全 的联合类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40#include <cassert>
#include <iostream>
#include <string>
#include <variant>
int main()
{
std::variant<int, float> v, w;
v = 42; // v contains int
int i = std::get<int>(v);
assert(42 == i); // succeeds
w = std::get<int>(v);
w = std::get<0>(v); // same effect as the previous line
w = v; // same effect as the previous line
// std::get<double>(v); // error: no double in [int, float]
// std::get<3>(v); // error: valid index values are 0 and 1
// 类型安全就是可以抛出异常并且捕获
try
{
std::get<float>(w); // w contains int, not float: will throw
}
catch (const std::bad_variant_access& ex)
{
std::cout << ex.what() << '\n';
}
using namespace std::literals;
std::variant<std::string> x("abc");
// converting constructors work when unambiguous
x = "def"; // converting assignment also works when unambiguous
std::variant<std::string, void const*> y("abc");
// casts to void const* when passed a char const*
assert(std::holds_alternative<void const*>(y)); // succeeds
y = "xyz"s;
assert(std::holds_alternative<std::string>(y)); // succeeds
}
12 委托构造函数
1 | |
- 构造函数构造对象时,确保构造路径只有一条,否则如果漏改了某些构造函数会出现问题
- 大量重复代码
- 所有的构造函数都依赖同一个初始函数
如果成员初始化都在 CommonInit 里面也会有其他问题
1 | |
c_并不是初始化,而是赋值操作- 对象的初始化在构造函数主题执行之前,也就是初始化列表阶段就已经执行了
- 用
CommonInit“初始化”c_其实对其进行了两次操作:一次初始化,另一次的赋值
有些情况时不能使用函数主体对成员对象进行赋值的
- 禁用了赋值运算符的数据成员 e.g.
class Y
- 禁用了赋值运算符的数据成员 e.g.
委托构造函数 C++ 11
- 某个类型的一个构造函数可以委托同类型的另一个构造函数对对象惊醒初始化
- 前者为委托构造函数
- 后者为代理构造函数
- 委托构造函数会将控制权交给代理构造函数,在代理构造函数执行完成之后,再执行委托构造函数的主体
- 路径是唯一了
1 | |
Note
每个构造函数都可以委托另一个构造函数为代理
不要递归循环委托
- 最好的习惯就是指定一个 主构造函数,其他构造函数都委托到这个主构造函数
- 就一个负重前行就可以了,不用折腾别的构造函数了
如果一个构造函数为委托构造函数,那么其初始化列表里就不能对数据成员和基类进行初始化
1
2
3
4
5
6
7
8
9
10
11class X
{
public:
X() : a_(0), b_(0) { CommonInit(); }
X(int a) : X(), a_(a) {} // 编译错误,委托构造函数不能在初始化列表初始化成员变量
X(double b) : X(), b_(b) {}// 编译错误,委托构造函数不能在初始化列表初始化成员变量
private:
void CommonInit() {}
int a_;
double b_;
};- 根据 C++ 标准规定,一旦类型有一个构造函数完成执行,那么就会认为其构造的对象已经构造完成
- 代理构造函数执行完成以后,编译器认为对象已经构造成功,再次执行初始化列表必然会导致不可预知的问题,所以 C++ 标准禁止了这样的语法
委托构造函数的执行顺序是先执行代理构造函数的初始化列表,然后执行代理构造函数的主体,最后执行委托构造函数的主体
如果在代理构造函数执行完成后,委托构造函数主体抛出了异常,则自动调用该类型的析构函数
委托模板构造函数 是指一个构造函数将控制权委托到同类型的一个模板构造函数,就是代理构造函数是一个函数模板
1 | |
- 捕获委托构造函数的异常
1 | |
使用 Function-try-block 的代码格式,也可以应用到普通函数上
- 委托参数较少的构造函数
- 通常情况下将参数较少的构造函数委托给参数较多的构造函数
- 也可以从参数较多的构造函数委托参数较少的构造函数,例如完成一些最基础的初始化工作
13 继承构造函数
1 | |
一个类有很多构造入口就不是一个很好的设计
Derived并不会自动继承Base里面所有的构造函数,所以要把基类所有的构造函数都要重新写一遍C++ 中可以使用
using关键字将基类的函数引入派生类C++ 11 将
using关键字的能力进行了扩展,使其能够引入基类的构造函数派生类
Derived使用using Base::Base让编译器为自己生成转发到基类的构造函数1
2
3
4
5class Derived : public Base {
public:
using Base::Base;
void SomeFunc() {}
};Note
派生类是隐式继承基类的构造函数,所以只有在程序中使用了这些构造函数,编译器才会为派生类生成继承构造函数的代码
派生类不会继承基类的默认构造函数和复制构造函数
- 继承基类的默认构造函数和默认复制构造函数的做法是多余的
继承构造函数不会影响派生类默认构造函数的隐式声明,也就是说对于继承基类构造函数的派生类,编译器依然会为其自动生成默认构造函数的代码
在派生类中声明签名相同的构造函数会禁止继承相应的构造函数
派生类继承多个签名相同的构造函数会导致编译失败
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Base1 {
public:
Base1(int) { std::cout << "Base1(int x)" << std::endl; };
};
class Base2 {
public:
Base2(int) { std::cout << "Base2(int x)" << std::endl; };
};
class Derived : public Base1, Base2 {
public:
using Base1::Base1;
using Base2::Base2;
};
int main() {
Derived d(5);
}- 编译器不知道用哪个
- 最好的解决办法就是不要搞多继承
继承构造函数的基类构造函数不能为私有
protected是可以的
继承基类构造函数时,不会继承默认参数
14 强枚举类型
枚举类型的弊端
一个枚举类型不允许分配到另外一种枚举类型
整型也无法隐式转换成枚举类型,枚举类型却可以隐式转换为整型
枚举类型会把其内部的枚举标识符导出到枚举被定义的作用域,这样重复定义的概率就变大了
1
2
3
4
5
6
7
8
9
10enum HighSchool {
student,
teacher,
principal
};
enum University {
student,
professor,
principal
};principal重定义了无法指定枚举类型的底层类型
- 不同的编译器对于相同枚举类型可能会有不同的底层类型
强枚举类型 C++ 11
- 枚举标识符属于强枚举类型的作用域
- 枚举标识符不会隐式转换为整型
- 能指定强枚举类型的底层类型,底层类型默认为 int 类型
- 在枚举定义的
enum关键字之后加上class关键字 - 相同类型可以比较,不同类型比较没有意义
- 可以通过
static_cast对其进行强制类型转换
列表初始化有底层类型枚举对象 C++ 17
从 C++ 17 标准开始,对有底层类型的枚举类型对象可以直接使用列表初始化
1
2
3
4
5
6
7
8
9
10
11enum class Color {
Red,
Green,
Blue
};
int main() {
Color c{ 5 }; // 编译成功
Color c1 = 5; // 编译失败
Color c2 = { 5 }; // 编译失败
Color c3(5); // 编译失败
}没有指定底层类型的枚举类型是无法使用列表初始化的
同所有的列表初始化一样,它禁止缩窄转换
1
2
3
4enum class Color : char {}
int main() {
Color c{ 7.11 };
}
使用
using打开强枚举类型 C++ 201
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18enum class Color {
Red,
Green,
Blue
};
const char* ColorToString(Color c)
{
switch (c)
{
using enum Color;
case Red: return "Red";
case Green: return "Green";
case Blue: return "Blue";
default:
return "none";
}
}
15 扩展的聚合类型
聚合类型
- 没有用户提供的构造函数
- 没有私有和受保护的非静态数据成员
- 可以类比于 C 结构体中的数据成员,因为都是
public
- 可以类比于 C 结构体中的数据成员,因为都是
- 没有虚函数
- 必须是公开的基类,不能是私有或者受保护的基类
- 必须是非虚继承
- 基类是否是聚合类型与派生类是否为聚合类型没有关系
- 在标准库
<type_traits>中提供了一个聚合类型的甄别办法is_aggregate,判断目标类型是否为聚合类型
聚合类型的初始化
1 | |
MyStringWithIndex是聚合类型,{"hello world"}是基类初始化方式,11是派生类的初始化方式{"hello world"}的大括号也可以省略,即MyStringWithIndex s{ "hello world", 11 }如果派生类存在多个基类,那么其初始化的顺序与继承的顺序相同
基类中的构造函数如果是受保护的关系,它不允许在聚合类型初始化中被调用
- 需要为派生类提供一个默认构造函数,就不是聚合类型了
用户 提供 的构造函数和用户 声明 的构造函数是有区别的
1
2
3
4
5
6
7
8
9
10
11
12
13#include <iostream>
struct X {
X() = default;
};
struct Y {
Y() = delete;
};
int main() {
std::cout << std::boolalpha << "std::is_aggregate_v<X> : " << std::is_aggregate_v<X> << std::endl;
std::cout << std::boolalpha << "std::is_aggregate_v<Y> : " << std::is_aggregate_v<Y> << std::endl;
}- C++ 17 认为类中存在用户声明的构造函数是聚合类型,所以
X和Y都是聚合类型
1
2Y y1; // 编译失败,使用了删除函数
Y y2{}; // 编译成功,聚合类型初始化- 这个问题很容易在真实的开发过程中被忽略,从而导致意想不到的结果
- 所以在 C++ 20 标准中禁止聚合类型使用用户声明的构造函数 C++ 20
- 用 C++20 环境编译后
X和Y都不是聚合类型了
- 用 C++20 环境编译后
- C++ 17 认为类中存在用户声明的构造函数是聚合类型,所以
使用带小括号的列表初始化聚合类型对象 C++ 20
1
2
3
4
5struct X {
int i;
float f;
};
X x(11, 7.0f);- 带大括号的列表初始化是不支持缩窄转换,但是带小括号的列表初始化却是支持缩窄转换的
16 override和 final
重写、重载和隐藏
- 重写(override):在 C++ 中是指派生类覆盖了基类的虚函数,这里的覆盖必须满足有相同的函数签名和返回类型,也就是说有相同的函数名、形参列表以及返回类型
- 重载(overload):它通常是指在同一个类中有两个或者两个以上函数,它们的函数名相同,但是函数签名不同,也就是说有不同的形参
- 隐藏(overwrite):隐藏是指基类成员函数,无论它是否为虚函数,当派生类出现同名函数时,如果派生类函数签名不同于基类函数,则基类函数会被隐藏。如果派生类函数签名与基类函数相同,则需要确定基类函数是否为虚函数,如果是虚函数,则这里的概念就是重写;否则基类函数也会被隐藏
- 如果还想使用基类函数,可以使用
using关键字将其引入派生类
- 如果还想使用基类函数,可以使用
override说明符
1 | |
- 派生类
Derived的 4 个函数都没有触发重写操作 - 稍不注意就会无法重写基类虚函数
- 即使写错了代码,编译器也可能不会提示任何错误信息,直到程序编译成功后,运行测试才会发现其中的逻辑问题
- C++ 11 标准提供了
override说明符 C++ 11override说明符必须放到虚函数的尾部- 告诉诉编译器这个虚函数需要覆盖基类的虚函数
- 编译器发现该虚函数不符合重写规则,会给出错误提示
- 基类如果改了成员函数,派生类却不知道,这个时候加上
override编译器就能检查出来了
1 | |
final说明符
- 可以为基类声明纯虚函数来迫使派生类继承并且重写这个纯虚函数
- C++ 11 标准引入 final 说明符来阻止派生类去继承基类的虚函数 C++ 11
override和final可以同时出现- 类定义的时候声明了
final,那么这个类将不能作为基类被其他类继承
1 | |
C++ 11 标准中,override和 final 并没有被作为保留的关键字,其中 override 只有在虚函数尾部才有意义,而 final 只有在虚函数尾部以及类声明的时候才有意义
1 | |
这样的代码都是可以的,为了兼容老代码
17 基于范围的 for 循环
C++ 11 标准引入了基于范围的
for循环特性,该特性隐藏了迭代器的初始化和更新过程 C++ 11for (range_declaration : range_expression) loop_statement,必须满足下面 2 个条件之一- 对象类型定义了
begin和end成员函数 - 定义了以对象类型为参数的
begin和end普通函数
- 对象类型定义了
对于复杂的对象使用引用,而对于基础类型使用值,因为这样能够减少内存的复制
如果不会在循环过程中修改引用对象,那么推荐在范围声明中加上
const限定符,免得犯错误C++ 11 标准中基于范围的
for循环相当于以下伪代码 C++ 111
2
3
4
5
6
7{
auto && __range = range_expression;
for (auto __begin = begin_expr, __end = end_expr; __begin != __end; ++__begin) {
range_declaration = *__begin;
loop_statement
}
}auto __begin = begin_expr, __end = end_expr;表明了begin和end必须类型相同,但是没有必要C++ 17 标准对基于范围的
for循环的实现进行了改进 C++ 171
2
3
4
5
6
7
8
9{
auto && __range = range_expression;
auto __begin = begin_expr;
auto __end = end_expr;
for (; __begin != __end; ++__begin) {
range_declaration = *__begin;
loop_statement
}
}
对于 auto && __range = range_expression;,如果range_expression 是一个纯右值,那么右值引用会扩展其生命周期,保证其整个 for 循环过程中访问的安全性。但如果 range_ expression 是一个泛左值,那结果可就不确定了
1 | |
因为 foo().items() 返回的是一个泛左值类型 std::vector<int>&,也就是在foo().items() 表达式的一瞬间是有用的,之后就找不到了,所以出现了 UB
对于这种情况将数据复制出来是一种解决方法
1 | |
在 C++ 20 标准中,基于范围的 for 循环增加了对初始化语句的支持 C++ 20
1 | |
18 支持初始化语句的 if 和switch
- 支持初始化语句的
if和switchC++ 17if控制结构可以在执行条件语句之前先执行一个初始化语句if (init; condition) {}- 其中
init是初始化语句,condition 是条件语句,它们之间使用分号分隔 - 变量的作用于不会泄露到外面
switch在通过条件判断确定执行的代码分支之前也可以接受一个初始化语句
19 static_assert声明
运行时断言
- 静态断言出现之前
- 只有在程序运行时才会起作用
- 直接终止程序,没有必要直接终止程序
- Release 断言都要关掉的
- 性能上也会有问题
静态断言
static_assertC++ 11- 所有处理必须在编译期间执行,不允许有空间或时间上的运行时成本
- 它必须具有简单的语法
- 断言失败可以显示丰富的错误诊断信息
- 它可以在命名空间、类或代码块内使用
- 失败的断言会在编译阶段报错
- 第一个实参必须是常量表达式,因为编译器无法计算运行时才能确定结果的表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#include <type_traits>
class A {};
class B : public A {};
class C {};
template<class T>
class E {
static_assert(std::is_base_of<A, T>::value, "T is not base of A");
};
int main(int argc, char *argv[]) {
static_assert(argc > 0, "argc > 0"); // 使用错误,argc>0 不是常量表达式
E<C> x; // 使用正确,但由于 A 不是 C 的基类,所以触发断言
static_assert(sizeof(int) >= 4, "sizeof(int) >= 4"); // 使用正确,表达式返回真,不会触发失败断言
E<B> y; // 使用正确,A 是 B 的基类,不会触发失败断言
}- 要使用单参数的
static_assertC++ 17
20 结构化绑定
- C++ 11 标准中同样引入了元组的概念,通过元组 C++ 也能返回多个值
1 | |
如果不使用 std::tie(x, y) 而是直接使用 std::tuple(x, y) 来接受返回值,即
1 | |
因为 std::tuple 构造函数参数不是引用,无法修改实参的值,而且返回的是一个临时对象,这一行语句结束后临时对象就失效,所以可以使用引用的形式接受返回值,即
1 | |
这样对比下来发现 x 的值改变了,y的值没有改变
- C++ 11 必须指定
return_multiple_values函数的返回值类型,提前声明变量 - 可以使用
auto的新特性来简化返回类型的声明 C++ 14 - 结构化绑定是指将一个或者多个名称绑定到初始化对象中的一个或者多个子对象(或者元素)上,相当于给初始化对象的子对象(或者元素)起了别名 C++ 17
深入理解结构化绑定
1 | |
经过解语法糖后
1 | |
绑定后的变量和原来的结构体中的数据不是同一块内存,是匿名构造了一个新的对象,然后引用原来对象中的数据成员,可以理解为原来对象成员变量的别名
只有匿名对象是原来对象的引用,才能够修改原来对象的数据
使用结构化绑定无法忽略对象的子对象或者元素
1
2auto t = std::make_tuple(42, "hello world");
auto [x] = t; // 编译报错在 C++ 11 标准下可以使用
std::tie加std::ignore解决1
2
3
4auto t = std::make_tuple(42, "hello world");
int x = 0, y = 0;
std::tie(x, std::ignore) = t;
std::tie(y, std::ignore) = t;但是结构化绑定的别名无法在同一个作用域中重复使用
1
2
3auto t = std::make_tuple(42, "hello world");
auto[x, std::ignore] = t;
auto[y, std::ignore] = t; // 编译错误,std::ignore 无法重复声明
结构化绑定的 3 中类型
- 绑定到原生数组
1 | |
绑定到结构体和类对象
类或者结构体中的非静态数据成员个数必须和标识符列表中的别名的个数相同
这些数据成员必须是公有的
- C++ 20 标准规定结构化绑定的限制不再强调必须为公开数据成员 C++ 20
这些数据成员必须是在同一个类或者基类中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class BindBase1 {
public:
int a = 42;
double b = 11.7;
};
class BindTest1 : public BindBase1 {};
class BindBase2 {};
class BindTest2 : public BindBase2 {
public:
int a = 42;
double b = 11.7;
};
class BindBase3 {
public:
int a = 42;
};
class BindTest3 : public BindBase3 {
public:
double b = 11.7;
};
int main() {
BindTest1 bt1;
BindTest2 bt2;
BindTest3 bt3;
auto[x1, y1] = bt1; // 编译成功
auto[x2, y2] = bt2; // 编译成功
auto[x3, y3] = bt3; // 编译错误
}定的类和结构体中不能存在匿名联合体
绑定到元组和类元组的对象
- 类元组就是像元组一样的东西 ,满足元组抽象的几种条件;对于元组或者类元组类型
T就跟 C++ 20 中的协程一样,只要按照某种模式写就行了- 需要满足
std::tuple_size<T>::value是一个符合语法的表达式,并且该表达式获得的整数值与标识符列表中的别名个数相同 能取到大小 - 类型
T还需要保证std::tuple_element<i, T>::type也是一个符合语法的表达式,其中i是小于std::tuple_size<T>::value的整数,表达式代表了类型T中第i个元素的类型 能取到类型 - 类型
T必须存在合法的成员函数模板get<i>()或者函数模板get<i>(t),其中i是小于std::tuple_size<T>::value的整数,t是类型T的实例,get<i>()和get<i>(t)返回的是实例t中第i个元素的值 能取到值
- 需要满足
- 类元组就是像元组一样的东西 ,满足元组抽象的几种条件;对于元组或者类元组类型
21 noexcept关键字
异常不仅是语法层的概念
很多语言都把异常作为逻辑的一部分
返回一个
optional,而不是抛异常,这样在发生异常的时候可以有选择的处理:是继续取里面的值还是向上传递optional是一个返回值,需要调用者去关心,去处理,但是异常就可能不受到关心移动构造函数中包含着一个严重的异常陷阱
- 在 C++ 11 之前,由于没有移动语义,只能将原始容器的数据复制到新容器中。如果在数据复制的过程中复制构造函数发生了异常,那么可以丢弃新的容器,保留原始的容器
- 但是有了移动语义,原始容器的数据会逐一地移动到新容器中,如果数据移动的途中发生异常,那么原始容器也将无法继续使用,因为已经有一部分数据移动到新的容器中
C++ 标准委员会提出了
noexcept说明符 C++ 11它既是一个说明符,也是一个运算符
作为说明符,它能够用来说明函数是否会抛出异常
noexcept只是告诉编译器不会抛出异常,但函数不一定真的不会抛出异常- 在声明了
noexcept的函数中抛出异常时,程序会调用std::terminate去结束程序的生命周期
作为运算符,
noexcept还能接受一个返回布尔的常量表达式- 当表达式 评估 为
true的时候,其行为和不带参数一样,表示函数不会抛出异常 - 当表达式 评估 为
false的时候,则表示该函数有可能会抛出异常 - 由于
noexcept对表达式的评估是在编译阶段执行的,因此表达式必须是一个常量表达式 - 广泛应用于模板当中,看到编译阶段执行,大概率给模板使用
1
2
3
4template <class T>
T copy(const T &o) noexcept(std::is_fundamental<T>::value) {
...
}- 只有在
T是一个基础类型时复制函数才会被声明为noexcept,因为基础类型的复制是不会发生异常的, - 如果
T是复杂类型么调用其复制构造函数是有可能发生异常的,直接声明noexcept会导致当函数遇到异常的时候程序被终止 noexcept运算符能够准确地判断函数是否有声明不会抛出异常- 还希望在类型
T的复制构造函数保证不抛出异常的情况下都使用noexcept声明
1
2
3
4template <class T>
T copy(const T &o) noexcept(noexcept(T(o))) {
...
}- 只不过两个
noexcept关键字发挥了不同的作用- 第二个关键字是运算符,它判断
T(o)是否有可能抛出异常 - 第一个
noexcept关键字则是说明符,它接受第二个运算符的返回值,以此决定T类型的复制函数是否声明为不抛出异常
- 第二个关键字是运算符,它判断
- 当表达式 评估 为
用 noexcept 来解决移动构造问题
现在 noexcept 运算符可以判断目标类型的移动构造函数是否有可能抛出异常。如果没有抛出异常的可能,那么函数可以选择进行移动操作;否则将使用传统的复制操作
1 | |
- 检查类型
T的移动构造函数和移动赋值函数是否都不会抛出异常 - 通过移动构造函数和移动赋值函数移动对象
a和b - 但是只进行了移动交换,当交换的两个对象在移动时可能抛出异常情况下,需要使用拷贝交换而不是移动交换
1 | |
只是不能让用,但是还是没有解决问题,最终的交换函数
1 | |
noexcept(T(std::move(a))) && noexcept(a.operator=(std:: move(b)))这段代码完全可以使用 std::is_nothrow_move_constructible<T>::value && std::is_nothrow_move_ assignable<T>::value 来代替
noexcept和throw()
throw()什么都不抛,就是没有异常
throw()能用的地方noexcept也可以用,反过来不行- 如果一个函数在声明了
noexcept的基础上抛出了异常,那么程序将不需要展开堆栈,它不会调用std::unexpected,而是调用std::terminate结束程序 throw()则需要展开堆栈,并调用std::unexpected- 在 C++ 17 标准中,
throw()成为noexcept的一个别名,throw()和noexcept拥有了同样的行为和实现 C++ 17 - 在 C++ 20 中
throw()被标准移除 C++ 20
默认使用 noexcept 的函数
- 默认构造函数、默认复制构造函数、默认赋值函数、默认移动构造函数和默认移动赋值函数会默认带有
noexcept声明- 对应的函数在类型的基类和成员中也具有
noexcept声明,否则其对应函数将不再默认带有noexcept声明 - 自定义实现的函数默认也不会带有
noexcept声明
- 对应的函数在类型的基类和成员中也具有
- 类型的析构函数以及
delete运算符默认带有noexcept声明- 即使自定义实现的析构函数也会默认带有
noexcept声明
- 即使自定义实现的析构函数也会默认带有
使用 noexcept 的时机
- 一定不会出现异常的函数。通常情况下,这种函数非常简短,例如求一个整数的绝对值、对基本类型的初始化等
- 目标是提供不会失败或者不会抛出异常的函数时可以使用
noexcept声明- 对于保证不会抛出异常的函数而言,即使有错误发生,函数也更倾向用返回错误码的方式而不是抛出异常 是 异常太粗暴了
22 类型别名和别名模板
往往会使用
typedef为较长的类型名定义一个别名- 实际上 C 语言中是比较常用的如
struct xxx、union xxx - C++ 中
struct xxx、union xxx定义后xxx就是类名,不需要typedef了
- 实际上 C 语言中是比较常用的如
新的定义类型别名的方法,使用
using关键字 C++ 111
2typedef void(*func1)(int, int);
using func2 = void(*)(int, int);对比
typedef更加清晰
typedef模板别名
1 | |
在上面这段代码中,类模板 X 没有确定模板形参 T 的类型,所以 int_map 是一个未决类型,也就是说 int_map 既有可能是一个类型,也有可能是一个静态成员变量,编译器是无法处理这种情况的。这里的 typename 关键字告诉编译器应该将 int_map 作为类型来处理
using模板别名
1 | |
别名模板不会有 ::type 的困扰,当然也不会有这样的问题了。当然,为了保证与老代码的兼容性,typedef的方案依然存在。别名模板的模板元编程函数使用 _t 作为其名称的后缀以示区分
23 指针字面量nullptr
NULL是一个宏,在 C++ 11 标准之前其本质就是 01
2
3
4
5
6
7#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif使用 0 代表不同类型的特殊规则给 C++ 带来了二义性
1
2
3
4
5
6
7
8
9
10void f(int) {
std::cout << "int" << std::endl;
}
void f(char *) {
std::cout << "char *" << std::endl;
}
f(NULL);
f(reinterpret_cast<char *>(NULL));f(NULL)会造成 UB1
2std::string s1(false);
std::string s2(true);false被隐式转换为 0,true不能隐式转换成 1,所以std::string s2(true)在 MSVC 中编译报错nullptr表示空指针的字面量 C++ 11它是一个
std::nullptr_t类型的纯右值不允许运用在算术表达式中或者与非指针类型进行比较(除了空指针常量 0)
可以隐式转换为各种指针类型,但是无法隐式转换到非指针类型
可以为函数模板或者类设计一些空指针类型的特化版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24#include <iostream>
template<class T>
struct widget {
widget() {
std::cout << "template" << std::endl;
}
};
template<>
struct widget<std::nullptr_t> {
widget() {
std::cout << "nullptr" << std::endl;
}
};
template<class T>
widget<T>* make_widget(T) {
return new widget<T>();
}
int main() {
auto w1 = make_widget(0);
auto w2 = make_widget(nullptr);
}
24 三向比较
C++ 20 标准新引入了一个名为“太空飞船”(spaceship)的运算符
<=>C++ 20运算符
<=>的返回值只能与 0 和自身类型来比较,如果同其他数值比较,编译器会报错三向比较的返回类型:
std::strong_ordering、std::weak_ordering以及std::partial_orderingstd::strong_ordering表达的是一种可替换性- 对于基本类型中的
int类型,三向比较返回的是std::strong_ordering - 默认情况下自定义类型是不存在三向比较运算符函数的,需要用户显式默认声明
- 对于基本类型中的
std::weak_ordering表达的是不可替换性- 基础类型中并没有,但是它常常发生在用户自定义类中,比如一个大小写不敏感的字符串类
std::partial_ordering表示进行比较的两个操作数没有关系- 基础类型中的浮点数
- 浮点的集合中存在一个特殊的 NaN(not a number),它和其他浮点数值是没关系的
对基础类型的支持
对两个算术类型的操作数进行一般算术转换,然后进行比较
- 整型的比较结果为
std::strong_ordering - 浮点型的比较结果为
std::partial_ordering
- 整型的比较结果为
对于无作用域枚举类型和整型操作数,枚举类型会转换为整型再进行比较,无作用域枚举类型无法与浮点类型比较
对两个相同枚举类型的操作数比较结果,如果枚举类型不同,则无法编译
对于其中一个操作数为
bool类型的情况,另一个操作数必须也是bool类型,否则无法编译不支持作比较的两个操作数为数组的情况,会导致编译出错
对于其中一个操作数为指针类型的情况,需要另一个操作数是同样类型的指针,或者是可以转换为相同类型的指针,比如数组到指针的转换、派生类指针到基类指针的转换等
1
2
3
4char arr1[5];
char arr2[5];
char* ptr = arr2;
auto r = ptr <=> arr1;
C++20 标准规定,如果用户为自定义类型声明了三向比较运算符,那么编译器会为其自动生成
<、>、<=和>=这 4 种运算符函数现在 C++ 20 标准已经推荐使用
<=>和==运算符自动生成其他比较运算符函数- 有了
<=>可以生成<、>、<=和>= - 有了
==可以生成!=
- 有了
在用户自定义类型中,实现了
<、==运算符函数的数据成员类型,在该类型的三向比较中将自动生成合适的比较代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct Legacy {
int n;
bool operator==(const Legacy& rhs) const {
return n == rhs.n;
}
bool operator<(const Legacy& rhs) const {
return n < rhs.n;
}
};
struct TreeWay {
Legacy m;
std::strong_ordering operator<=>(const TreeWay &) const = default;
};
TreeWay t1, t2;
bool r = t1 < t2;结构体
TreeWay的三向比较操作会调用结构体Legacy中的<和==运算符来完成
25 线程局部存储
线程局部存储是指对象内存在线程开始后分配,线程结束时回收且每个线程有该对象自己的实例
thread_local说明符可以用来声明线程生命周期的对象- 能与
static或extern结合,分别指定内部或外部链接 - 和
static类似,但是在多线程访问时thread_local修饰的变量在每个线程中是独立的,static修饰的变量在线程之间是一份内存
- 能与
使用取地址运算符
&取到的线程局部存储变量的地址是运行时被计算出来的,它不是一个常量,也就是说无法和constexpr结合1
2
3
4
5
6
7thread_local int tv;
static int sv;
int main()
{
constexpr int *sp = &sv; // 编译成功,sv 的地址在编译时确定
constexpr int *tp = &tv; // 编译失败,tv 的地址在运行时确定
}线程局部存储对象的初始化和销毁。在同一个线程中,一个线程局部存储对象只会初始化一次
对象的销毁也只会发生一次,通常发生在线程退出的时刻
26 扩展的 inline 说明符
- 在 C++ 17 标准之前,非常量静态成员变量的声明和定义必须分开进行
include是单纯的宏替换 以小博大,谓之“宏”
- C++ 17 增强了
inline说明符的能力,它允许我们内联定义静态变量 C++ 17
1 | |
针对于 inline 函数,有时候并不一定需要用户手动去指定,编译器会做优化;也就是说编译器也会决定哪些函数是可以内联的,很多时候能覆盖绝大多数的场景
27 常量表达式
宏定义或这常量定义
1 | |
- C++ 程序员应该尽量少使用宏,因为预处理器对于宏只是简单的字符替换,完全没有类型检查,而且宏使用不当出现的错误难以排查
- 可以用模板代替
将宏或常量改为函数调用
1 | |
无法通过编译,无论是宏定义的函数调用,还是通过函数返回值初始化 const 变量都是在运行时确定的
C 语言中可支持在栈上开辟变长数组(VLA),C++ 没有必要
- C 语言
<limit.h>中定义了各种整型类型的最大值和最小值,是通过宏定义的 - C++ 为了避免宏的使用,在
<limit>中采用模板特化的方式来定义最值,返回的是函数计算后的值,但是必须在运行时计算,仍然会导致常量无法确定的问题char buffer[std::numeric_limits<unsigned char>::max()] = {0};编译报错
- C++ 11 标准中定义一个新的关键字
constexpr,它能够有效地定义常量表达式 C++ 11
constexpr值和函数
constexpr 值即常量表达式值,是一个用 constexpr 说明符声明的变量或者数据成员,它要求该值必须在编译期计算 常量表达式值必须由常量表达式初始化
1 | |
constexpr是一个加强版的const,它不仅要求常量表达式是常量,并且要求是一个编译阶段就能够确定其值的常量常量和常量是不一样的
- 编译器 / 编译时常量
- 数值类型,
bool类型,字符串类型
- 数值类型,
- 运行期 / 运行时常量
- 编译器 / 编译时常量
constexpr函数,常量表达式函数的返回值可以在编译阶段就计算出来- 函数必须返回一个值,所以它的返回值类型不能是
void - 函数体必须只有一条语句:
return expr,其中expr必须也是一个常量表达式。如果函数有形参,则将形参替换到expr中后,expr仍然必须是一个常量表达式 - 函数使用之前必须有定义
- 函数必须用
constexpr声明
- 函数必须返回一个值,所以它的返回值类型不能是
虽然常量表达式函数的返回值可以在编译期计算出来,但是这个行为并不是确定的
- 当带形参的常量表达式函数接受了一个非常量实参时,常量表达式函数可能会退化为普通函数
constexpr构造函数构造函数必须用
constexpr声明构造函数初始化列表中必须是常量表达式
构造函数的函数体必须为空(这一点基于构造函数没有返回值,所以不存在
return expr)1
2
3
4
5
6
7
8
9
10
11
12
13class X {
public:
constexpr X() : x1(5) {}
constexpr X(int i) : x1(i) {}
constexpr int get() const {
return x1;
}
private:
int x1;
};
constexpr X x;
char buffer[x.get()] = { 0 };- 称这样的类为字面量类类型(literal class type)
constexpr会自动给函数带上const属性- 常量表达式构造函数拥有和常量表达式函数相同的退化特性,当它的实参不是常量表达式的时候,构造函数可以退化为普通构造函数
使用
constexpr声明自定义类型的变量,必须确保这个自定义类型的析构函数是平凡的,否则也是无法通过编译的- 自定义类型中不能有用户自定义的析构函数
- 析构函数不能是虚函数
- 基类和成员的析构函数必须都是平凡的
constexpr说明符则支持声明浮点类型的常量表达式值,而且标准还规定其精度必须至少和运行时的精度相同1
2
3
4
5constexpr double sum(double x) {
return x > 0 ? x + sum(x - 1) : 0;
}
constexpr double x = sum(5);
常量表达式函数的增强 C++ 14
函数体允许声明变量,除了没有初始化、
static和thread_local变量函数允许出现
if和switch语句,不能使用goto语句函数允许所有的循环语句,包括
for、while、do-while函数可以修改生命周期和常量表达式相同的对象
1
2
3
4
5constexpr int next(int x) {
return ++x;
}
char buffer[next(5)] = { 0 };x的声明周期和常量的生命周期一致函数的返回值可以声明为
voidconstexpr声明的成员函数不再具有const属性除了在常量表达式函数特性方面做了增强,也在标准库方面做了增强,包括
<complex>、<chrono>、<array>、<initializer_list>、<utility>和<tuple>
constexprlambda 表达式和内联属性
lambda 表达式在条件允许的情况下都会隐式声明为
constexprC++ 17当 lambda 表达式不满足
constexpr的条件时也没有关系,变成运行时的 lambda 表达式,只要用在合适的地方就可以了可以强制要求 lambda 表达式是一个常量表达式,用
constexpr去声明它即可- 可以检查 lambda 表达式是否有可能是一个常量表达式,如果不能则会编译报错
constexpr声明静态成员变量时,也被赋予了该变量的内联属性 C++ 171
2
3
4class X {
public:
static constexpr int num{ 5 };
};- C++ 11 中
num只有声明没有定义,实际上是编译器直接将X::num替换为5,如果对num取地址,即&X::num连接器会提示X::num缺少定义 - C++ 17 中
num{ 5 }既是声明也是定义
- C++ 11 中
if constexpr
该特性只有在使用模板的时候才具有实际意义,如果是普通函数,那直接可以写出分支中的语句即可;模板的类型只有实例化的时候才会出现不同的分支情况,使用 if constexpr 才有意义
if constexpr的条件必须是编译期能确定结果的常量表达式- 条件结果一旦确定,编译器将只编译符合条件的代码块
if constexpr不支持短路规则
1 | |
1 | |
float有效位数是 7 位,一般用 0.0000001 比较;double有效位数是 15 位,所以要多写几位,如 0.000000000000001 比较
使用 if constexpr 表达式,代码会简化很多而且更加容易理解
1 | |
需要注意这样一种陷阱
正常情况
1 | |
缺少 else 分支
1 | |
可能会导致函数有多个不同的返回类型;当实参类型为 double 的时,if的代码块会被正常地编译,代码块内部的返回结果类型为double,而代码块外部返回类型为int。编译器遇到了两个不同的返回类型,只能报错
constexpr其他特性 C++ 20
允许
constexpr虚函数constexpr的虚函数可以覆盖重写普通虚函数- 普通虚函数也可以覆盖重写
constexpr的虚函数 - 大不了就退化
允许在
constexpr函数中出现try-catch1
2
3
4
5constexpr int f(int x)
{
try { return x + 1; }
catch (...) { return 0; }
}try-catch和if-else是一个意思允许在
constexpr中进行平凡的默认初始化- 应该养成声明对象时随手初始化的习惯,避免让代码出现未定义的行为
允许在
constexpr中更改联合类型的有效成员1
2
3
4
5
6
7
8
9
10
11union Foo {
int i;
float f;
};
constexpr int use() {
Foo foo{};
foo.i = 3;
foo.f = 1.2f; // C++20 之前编译失败
return 1;
}使用
consteval声明立即函数,对于无法在编译期执行计算的情况则让编译器直接报错1
2
3
4
5
6
7consteval int sqr(int n) {
return n * n;
}
constexpr int r = sqr(100); // 编译成功
int x = 100;
int r2 = sqr(x); // 编译失败- lambda 表达式也可以使用
consteval说明符
- lambda 表达式也可以使用
使用
constinit检查常量初始化,要用于具有静态存储持续时间的变量声明上,它要求变量具有常量初始化程序constinit说明符作用的对象是必须具有静态存储持续时间的1
2
3
4
5constinit int x = 11; // 编译成功,全局变量具有静态存储持续
int main() {
constinit static int y = 42; // 编译成功,静态变量具有静态存储持续
constinit int z = 7; // 编译失败,局部变量是动态分配的
}constinit要求变量具有常量初始化程序1
2
3
4const char* f() { return "hello"; }
constexpr const char* g() { return "cpp"; }
constinit const char* str1 = f(); // 编译错误,f() 不是一个常量初始化程序,编译的时候不能确定其值
constinit const char* str2 = g(); // 编译成功,编译的时候可以确定其值虽然
constinit说明符一直在强调常量初始化,但是初始化的对象并不要求具有常量属性
std::is_constant_evaluated是 C++ 20 新加入标准库的函数,它用于检查当前表达式是否是一个常量求值环境1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#include <cmath>
#include <type_traits>
constexpr double power(double b, int x) {
if (std::is_constant_evaluated() && x >= 0) {
double r = 1.0, p = b;
unsigned u = (unsigned)x;
while (u != 0) {
if (u & 1) r *= p;
u /= 2;
p *= p;
}
return r;
} else {
return std::pow(b, (double)x);
}
}
int main() {
constexpr double kilo = power(10.0, 3); // 常量求值
int n = 3;
double mucho = power(10.0, n); // 非常量求值
return 0;
}明显常量求值
- 常量表达式,这个类别包括很多种情况,比如数组长度、
case表达式、非类型模板实参等 if constexpr语句中的条件constexpr变量的初始化程序- 立即函数调用
- 约束概念表达式
- 可在常量表达式中使用或具有常量初始化的变量初始化程序
1
2
3
4
5
6
7
8
9
10
11template<bool> struct X {};
X<std::is_constant_evaluated()> x; // 非类型模板实参,函数返回 true,最终类型为 X<true>
int y;
constexpr int f() {
const int n = std::is_constant_evaluated() ? 13 : 17; // n 是 13
int m = std::is_constant_evaluated() ? 13 : 17; // m 可能是 13 或者 17,取决于函数环境
char arr[n] = {}; // char[13]
return m + sizeof(arr);
}
int p = f(); // m 是 13;p 结果如下 26
int q = p + f(); // m 是 17;q 结果如下 56- 常量表达式,这个类别包括很多种情况,比如数组长度、
28 确定的表达式求值顺序
在 C++ 17 之前是没有具体说明的,所以编译器可以以任何顺序对子表达式进行求值
foo(a, b, c),这里的foo、a、b和c的求值顺序是没有确定的
函数表达式一定会在函数的参数之前求值 C++ 17
foo(a, b, c),foo一定会在a、b和c之前求值- 但是参数之间的求值顺序依然没有确定
对于后缀表达式和移位操作符而言,表达式求值总是从左往右
1
2
3
4
5
6E1[E2]
E1.E2
E1.*E2
E1->*E2
E1<<E2
E1>>E2在上面的表达式中,子表达式求值
E1总是优先于E2对于赋值表达式,这个顺序又正好相反,它的表达式求值总是从右往左
1
2
3
4
5
6E1=E2
E1+=E2
E1-=E2
E1*=E2
E1/=E2
...在上面的表达式中,子表达式求值
E2总是优先于E1对于
new表达式,C++ 17 也做了规定 C++ 171
new T(E)- 这里
new表达式的内存分配总是优先于T构造函数中参数E的求值 - 涉及重载运算符的表达式的求值顺序应由与之相应的内置运算符的求值顺序确定,而不是函数调用的顺序规则
- 这里
- 尽量不要使函数调用产生副作用,否则会很难确认实参的真实值
- 通过变成规范避免产生这种问题
- 在函数中不要既要修改又要访问
29 字面量优化
标准库中引入了
std::hexfloat和std::defaultfloat来修改浮点输入和输出的默认格式化 C++ 11std::hexfloat可以将浮点数格式化为十六进制的字符串std::defaultfloat可以将格式还原到十进制
二进制整数字面量也有前缀
0b和0BC++ 14- 十六进制
0x,0X和八进制0
- 十六进制
一个用单引号作为整数分隔符的特性 C++ 14
1
2
3
4constexpr int x = 123'456;
static_assert(x == 0x1e'240);
static_assert(x == 036'11'00);
static_assert(x == 0b11'110'001'001'000'000);- 单引号整数分隔符对于十进制、八进制、十六进制、二进制整数都是有效的
'加哪都可以
原生字符串字面量 raw string C++ 11
- 原生字符串字面量声明是
R"(raw_characters)",特殊字符不需要转义了
- 原生字符串字面量声明是
用户自定义字面量 C++ 11
- 可以通过自定义后缀将整数、浮点数、字符和字符串转化为特定的对象
- 字面量运算符函数的语法规则
- 由返回类型、
operator关键字、标识符以及函数形参组成的 retrun_type operator "" identifier (params)- 在 C++ 11 的标准中,双引号和紧跟的标识符中间必须有空格
- 标识符可以紧跟在双引号后 C++ 14
- 还能使用 C++ 的保留字作为标识符 C++ 14
- 建议用户定义的字面量运算符函数的标识符应该以下画线开始
- 由返回类型、
- 整数字面量运算符函数有 3 种不同的形参类型
unsigned long longconst char *- 形参为空
- 使用模板参数实现:
operator ""identifier<char…c>()
- 使用模板参数实现:
- 编译器会将整数字面量转换为对应的无符号
long long类型或者常量字符串类型,然后将其作为参数传递给运算符函数
- 浮点数字面量运算符函数有 3 种形参类型
long doubleconst char *- 形参为空
- 字符串字面量运算符函数
- 形参类型列表为
const char * str, size_t lenstr为字符串字面量的具体内容len是字符串字面量的长度
- 字符字面量运算符函数也只有一种形参类型
char
- 形参类型列表为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32#include <string>
unsigned long long operator "" _w1(unsigned long long n) {
return n;
}
const char * operator "" _w2(const char *str) {
return str;
}
unsigned long long operator "" _w3(long double n) {
return n;
}
std::string operator "" _w4(const char* str, size_t len) {
return str;
}
char operator "" _w5(char n) {
return n;
}
unsigned long long operator ""if(unsigned long long n) {
return n;
}
int main() {
auto x1 = 123_w1;
auto x2_1 = 123_w2;
auto x2_2 = 12.3_w2;
auto x3 = 12.3_w3;
auto x4 = "hello world"_w4;auto x5 = 'a'_w5;auto x6 = 123if;
}字面量运算符函数使用模板参数的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <string>
template <char…c> std::string operator "" _w() {
std::string str;
//(str.push_back(c), …); // C++17 的折叠表达式
using unused = int[]; // 为了避免歧义,导致编译器报错,如果使用
unused{ (str.push_back(c), 0) … };
// int[]{ (str.push_back(c), 0) … }; 类似结构化绑定,会导致编译器报错
return str;
}
int main() {
auto x = 123_w;
auto y = 12.3_w;
}unused{ (str.push_back(c), 0) … };如果使用的是123_w实际上可以展开为unused{ (str.push_back(1), 0), (str.push_back(2), 0), (str.push_back(3), 0),每个表达式的结果都是0,因为使用了逗号表达式,所以unused最终没有用到,目的是驱动这个表达式的计算
30 alignas和alignof
alignof运算符可以用于获取类型的对齐字节长度alignas说明符可以用来改变类型的默认对齐字节长度在
alignof运算符被引入之前,常用offsetof来间接实现alignof的功能1
2
3
4
5
6#define ALIGNOF(type, result) \
struct type##_alignof_trick{ char c; type member; }; \
result = offsetof(type##_alignof_trick, member)
int x1 = 0;
ALIGNOF(int, x1);其中
offsetof在 mscv 中实现也是一个宏 01
#define offsetof(s, m) ((::size_t)&reinterpret_cast<char const volatile&>((((s*)0)->m)))reinterpret_cast<char const volatile&>是编译器优化所用,理解时可以去掉,就是相对于地址 0 的偏移使用
alignof运算符1
2
3
4auto x1 = alignof(int);
auto x2 = alignof(void(*)());
int a = 0;
auto x3 = alignof(a); // *C++ 标准不支持这种用法- C++ 标准规定
alignof必须是针对类型的 - GCC 扩展了这条规则,
alignof除了能接受一个类型外还能接受一个变量 - 使用 MSVC 如果想获得变量的对齐,可以使用编译器的扩展关键字
__alignof - 可以通过
alignof获得类型std::max_align_t的对齐字节长度 - C++ 11 定义了
std::max_align_t,它是一个平凡的标准布局类型,其对齐字节长度要求至少与每个标量类型一样严格 - 所有的标量类型都适应
std::max_align_t的对齐字节长度 new和 malloc之类的分配函数返回的指针需要适合于任何对象,也就是说内存地址至少与std::max_align_t严格对齐
- C++ 标准规定
使用
alignas说明符- 该说明符可以接受类型或者常量表达式 该常量表达式计算的结果必须是一个 2 的幂值,否则是无法通过编译的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49#include <iostream>
struct X {
char a1;
int a2;
double a3;
};
struct X1 {
alignas(16) char a1;
alignas(double) int a2;
double a3;
};
struct alignas(16) X2 {
char a1;
int a2;
double a3;
};
struct alignas(16) X3 {
alignas(8) char a1;
alignas(double) int a2;double a3;
};
struct alignas(4) X4 {
alignas(8) char a1;
alignas(double) int a2;double a3;
};
#define COUT_ALIGN(s) std::cout << "alignof(" #s ") = " << alignof(s) <<std::endl
int main() {
X x;
X1 x1;
X2 x2;
X3 x3;
X4 x4;
alignas(4) X3 x5;
alignas(16) X4 x6;
COUT_ALIGN(x);
COUT_ALIGN(x1);
COUT_ALIGN(x2);
COUT_ALIGN(x3);
COUT_ALIGN(x4);
COUT_ALIGN(x5);
COUT_ALIGN(x6);
COUT_ALIGN(x5.a1);
COUT_ALIGN(x6.a1);
}- 既可以用于结构体,也可以用于结构体的成员变量
- 如果将
alignas用于结构体类型,那么该结构体整体就会以alignas声明的对齐字节长度进行对齐 - 结构体类型的对齐字节长度总是需要大于或者等于其成员变量类型的对齐字节长度
- 结构体类型的对齐字节长度,并不能影响声明变量时变量的对齐字节长度
提供了
std::alignment_of、std::aligned_storage和std::aligned_union类模板型以及std::align函数模板来支持对于对齐字节长度的控制1
2
3
4
5
6
7
8
9
10std::cout << std::alignment_of<int>::value << std::endl; // 输出 4
std::cout << std::alignment_of<int>() << std::endl; // 输出 4
std::cout << std::alignment_of<double>::value << std::endl; // 输出 8
std::cout << std::alignment_of<double>() << std::endl; // 输出 8
std::aligned_storage<128, 16>::type buffer;
std::cout << sizeof(buffer) << std::endl; // 内存大小指定为 128 字节
std::cout << alignof(buffer) << std::endl; // 对齐字节长度指定为 16 字节
std::aligned_union<64, double, int, char>::type buffer;
std::cout << sizeof(buffer) << std::endl; // 内存大小指定为 64 字节
std::cout << alignof(buffer) << std::endl; // 对齐字节长度自动选择为 double,8 字节对齐使用
new分配指定对齐字节长度的对象 C++ 17- 通过让
new运算符接受一个std::align_val_t类型的参数来获得分配对象需要的对齐字节长度 - 编译器会自动从类型对齐字节长度的属性中获取这个参数并且传参,不需要额外的代码介入
- 通过让
31 属性说明符和标准属性
标准属性说明符语法 C++ 11
[[attr]] [[attr1, attr2, attr3(args)]] [[namespace::attr(args)]]- 可以有一个属性,也可以有多个属性,也可以带参数,还可以存在
namespace - C++ 11 标准的属性说明符可用在 C++ 程序中的几乎所有位置
- 属性说明符总是声明位于其之前的对象,而在整个声明之前的属性则会声明语句中所有声明的对象
[[attr1]] class [[attr2]] X { int i; } a, b[[attr3]];- 到 C++ 20 为止,绝大部分标准属性在声明中使用
使用
using打开属性的命名空间,可直接使用命名空间的属性从而减少代码冗余 C++ 17[[using attribute-namespace : attribute-list]]- 编译器应该忽略任何无法识别的属性
标准属性
noreturnC++ 11- 回类型为
void说明函数还是会返回到调用者,只不过没有返回值 - 用
noreturn属性声明的函数编译器会认为在这个函数中执行流会被中断,函数不会返回到其调用者
1
2
3
4
5
6
7
8[[noreturn]] void foo() {}
void bar() {}
int main()
{
foo();
bar();
}在对
foo添加noreturn属性以后,main函数中编译器不再为调用foo后面的过程生成代码了,它不仅忽略了对bar函数的调用,甚至干脆连main函数里的栈平衡以及返回代码都忽略了。因为编译器被告知,调用foo函数之后程序的执行流会被中断,所以生成的代码一定不会被执行,索性也不需要生成这些代码了- 回类型为
carries_dependencyC++ 11deprecaetdC++ 14- 带有此属性的实体被声明为弃用
- 不仅能用在类、结构体和函数上,在普通变量、别名、联合体、枚举类型甚至命名空间上都可以使用
fallthroughC++ 17- 该属性可以在
switch语句的上下文中提示编译器直落行为是有意的,并不需要给出警告
- 该属性可以在
nodiscardC++ 17该属性声明函数的返回值不应该被舍弃
nodiscard属性也可以声明在类或者枚举类型上- 对类或者枚举类型本身并不起作用,只有当被声明为
nodiscard属性的类或者枚举类型被当作函数返回值的时候才发挥作用 nodiscard属性只适用于返回值类型的函数,对于返回引用的函数使用nodiscard属性是没有作用的
1
2
3
4
5
6
7
8
9
10class[[nodiscard]] X{};
[[nodiscard]] int foo() { return 1; }
X bar1() { return X(); };
X& bar2(X &x) { return x; };
int main() {
X x;
foo(); // 编译器发出警告
bar1(); // 编译器发出警告
bar2(x); // bar 返回引用,nodiscard 不起作用,不会引发警告
}- 对类或者枚举类型本身并不起作用,只有当被声明为
nodiscard属性支持将一个字符串字面量作为属性的参数 C++ 20nodiscard属性还能用于构造函数,它会在类型构建临时对象的时候让编译器发出警告 C++ 201
2
3
4
5
6
7
8
9
10
11class X {
public:
[[nodiscard]] X() {}
X(int a) {}
};
int main() {
X x;
X{}; // `X{}` 构造了临时对象,于是编译器给出忽略 `X::X()` 返回值的警告
X{ 42 };
}
maybe_unusedC++ 17- 该属性声明实体可能不会被应用以消除编译器警告
- 还可以用在如类、结构体、联合类型、枚举类型、函数、变量等地方
likely和unlikelyC++ 20likely属性允许编译器对该属性所在的执行路径相对于其他执行路径进行优化unlikely属性恰恰相反
1
2
3
4
5int f(int i) {
switch(i) {
case 1: return 1;
[[unlikely]] case 2: return 2;}return 3;
}编译在分支语句面前会做预判,对概率大的优先执行,如果执行的分支不是预测的,就直接将执行结果丢掉即可,再重新进行执行判断正确的语句
no_unique_addressC++ 20- 该属性指示编译器该数据成员不需要唯一的地址,也就是说它不需要与其他非静态数据成员使用不同的地址
- 是不是可与理解为不占用其他非静态数据成员的地址
32 新增预处理器和宏
预处理器
__has_includeC++ 17- 用于判断某个头文件是否能够被包含进来
- 可以替换实验性的头文件
特性测试宏 C++ 20 测试当前的编译环境对各种功能特性的支持程度
- 属性特性测试宏
__has_cpp_attribute- 指示编译环境是否支持某种属性
std::cout << __has_cpp_attribute(deprecated); // 输出结果如下:201309
- 语言功能特性测试宏
- 编译环境所支持的语言功能特性
__cpp_concepts,__cpp_constexpr等等
- 标准库功能特性测试宏
- 编译环境所支持的标准库功能特性
- 判断起来很麻烦,直接查表更方便
- 属性特性测试宏
新增宏
VA_OPT__VA_ARGS__常见的用法集中于打印日志上1
2#define LOG(msg, …) printf("[" __FILE__ ":%d] " msg, __LINE__, __VA_ARGS__)
LOG("Hello %d", 2020);对于
LOG宏来说,这种写法是非法的1
LOG("Hello 2020");上面这句代码展开后应该是
1
printf("[" __FILE__ ":%d] " "Hello 2020", __LINE__, );可以使用 ## 连接逗号和
__VA_ARGS__1
2#define LOG(msg, …) printf("[" __FILE__ ":%d] " msg, __LINE__, ##__VA_ARGS__)
LOG("Hello 2020");引入了一个新的宏__VA_OPT__令可变参数宏更易于在可变参数为空的情况下使用
1
#define LOG(msg, …) printf("[" __FILE__ ":%d] " msg, __LINE__ __VA_OPT__(,) __VA_ARGS__)观察上面的代码可以发现,
__LINE__后面的逗号被修改为__VA_OPT__(,),这是告诉编译器这个逗号是可选的
33 协程
协程是一种可以被挂起和恢复的函数,它提供了一种创建 异步 代码的方法
协程的使用方法
1 | |
co_await、co_return和 co_yield,具有以上 3 个关键字中任意一个的函数就是协程 C++ 20- 建议将协程和标准库中的
future、generator一起使用 - 协程虽然提供了一种异步代码的编写方法,但是并不会自动执行异步操作
协程的实现原理
1 | |
co_await运算符原理
目标对象可被等待需要实现 await_resume、await_ready和 await_suspen 这 3 个成员函数
await_ready函数叫作is_ready或许更加容易理解,该函数用于判定可等待体是否已经准备好,也就是说可等待体是否已经完成了目标任务,如果已经完成,则返回true;否则返回falseawait_suspend这个函数名则更加令人难以理解,命名为schedule_continuation应该会更加清晰,它的作用就是调度协程的执行流程,比如异步等待可等待体的结果、恢复协程以及将执行的控制权返回调用者- 形参
coroutine_handle<>,正如它的类型名所示,它是协程的句柄,可以用于控制协程的运行流程 - 有
operator()和resume()函数,它们可以执行挂起点之后的代码 await_suspend不一定返回void类型,还可以返回bool和coroutine_handle类型- 返回
void类型表示协程需要将执行流的控制权交给调用者,协程保持挂起状态 - 返回
bool类型则又会出现两种情况,当返回值为true时,效果和返回类型与void相同;当返回false的时候,则恢复当前协程运行 - 返回
coroutine_handle类型的时候,则会恢复该句柄对应的协程 - 如果在
await_suspend中捕获到了异常,那么协程也会恢复并且在协程中抛出该异常
- 返回
- 形参
await_resume实际上用于接收异步执行结果,可以叫作retrieve_value- 可以重载
co_await运算符,让它从可等待体转换为等待器
co_yield运算符原理
promise_type可以用于自定义协程自身行为,代码的编写者可以自定义协程的多种状态以及自定义协程中任何co_await、co_return或co_yield表达式的行为,比如挂起前和恢复后的处理、如何返回最终结果等- 通常情况下
promise_type会作为函数的嵌套类型存在 - 协程需要
promise_type帮助它返回一个对象,这个辅助函数就是get_return_object - 等待器
suspend_always和suspend_never,分别表示必然挂起和从不挂起 yield_value的意思很简单,保存co_yield操作数的值并且返回等待器generator通常返回suspend_always- 事实上,
co_yield i;可以等价于代码co_await promise.yield_value(i);
return_void用于实现没有co_return的情况。promise_type中必须存在return_void或者return_value
co_return运算符原理
co_return也需要promise_type的支持- 如果
co_return没有任何返回值,则需要用成员函数void return_void()代替void return_value(int value)
promise_type的其他功能
promise_type还有一个额外的功能,即可对co_await的操作数进行转换处理1
2
3
4struct promise_type {
…
awaitable await_transform(expr e) { return awaitable(e); }
};这样做的结果是代码
co_await expr;最终会转换为:co_await promise.await_transform(expr);promise_type还可以对异常进行处理1
2
3
4
5
6struct promise_type {
…
void unhandled_exception() {
eptr_ = std::current_exception();
}
};
34 基础特性的其他他优化
显示自定义类型转换运算符
- 隐式的行为总是会造成意想不到的错误,尽可能减少一些隐式的行为
std::unique_ptr定义了显示bool类型转换运算符来指示智能指针的内部指针是否为空std::ifstream定义了显示bool类型转换运算符来指示是否成功打开了文件目录- …
关于
std::launder()C++ 171
2
3
4
5template<typename T>
constexpr T* launder(T* p) noexcept
{
return p;
}洗内存,它的目的是防止编译器追踪到数据的来源以阻止编译器对数据的优化
返回值优化
允许编译器将函数返回的对象直接构造到它们本来要存储的变量空间中而不产生临时对象。返回值优化分为 RVO(Return Value Optimization)和 NRVO(Named Return Value Optimization),当返回语句的操作书为临时对象时,称之为 RVO;当返回语句的操作数为具名对象时,称之为 NRVO
实际上返回值优化是很容易失效的,不能在编译期的可以构造的对象会导致返回值优化失效
- C++ 14 标准中明确了对于常量表达式和常量初始化而言,编译器应该保证 RVO,但是禁止 NRVO C++ 14
- 在 C++ 17 标准中,在传递临时对象或者从函数返回临时对象的情况下,编译器应该省略对象的复制和移动构造函数,即使这些构造函数还有一些额外的作用,最终还是直接将对象构造到目标的存储变量上,从而避免临时对象的产生 C++ 17
允许按值进行默认比较
支持
new表达式推导数组长度1
2
3
4int x[]{ 1, 2, 3 }; // 可以编译通过,正常初始化
char s[]{ "hello world " }; // 可以编译通过,正常初始化
int *x = new int[]{ 1, 2, 3 }; // C++ 20 之前无法编译通过
char *s = new char[]{ "hello world " }; // C++ 20 之前无法编译通过允许数组转换为位置范围的数组
1
2
3
4
5
6
7void f(int(&)[]) {}
int arr[1];
int main()
{
f(arr);
int(&r)[] = arr;
}看上去没有比指针好在哪里
在
delete运算符函数中析构对象调用伪析构函数结束对象生命周期
修复
const和默认复制构造函数不匹配造成无法编译的问题不推荐使用
volatile的情况不推荐在下表表达式中使用逗号运算符
模块
35 可变参数模板
可变参数模板概念和语法
1 | |
class ...Args是类型模板参数包(parameter pack),Args ..args叫做函数形参包- 在类模板中,模板形参包必须是模板形参列表的最后一个形参
- 非类型模板形参也可以作为形参包,而且相对于类型形参包,非类型形参包更加直观
1
2
3
4
5
6
7
8
9
10
11template<int ...Args>
void foo() {};
template<int ...Args>
class bar {};
int main()
{
foo<1, 2, 3, 4>();
bar<1, 2, 3> b;
}
形参包展开
允许包展开的场景包括一下几种
- 表达式列表
- 初始化列表
- 基类描述
- 成员初始化列表
- 函数参数列表
- 模板参数列表
- 动态异常列表(C++ 17 已经不在使用)
- lambda 表达式捕获列表
sizeof运算符- 可以获取实际形参的个数
- 对齐运算符
- 属性列表
1 | |
(std::cout << args(7, 11) << std::endl, 0)逗号表达式求值,返回的是0
折叠表达式 C++ 17
一元向左折叠
{ ... op args}折叠为((((arg0 op arg1) op arg2) op ...) op argN)一元向右折叠
{ args op ... }折叠为(arg0 op ... (argN-1 op argN))二元向左折叠
二元向右折叠 相对于一元,多了一个初始值
{ args op ... op init }折叠为(arg1 op ... (argN-1 op (argN op init)))1
2
3
4
5
6
7
8
9
10
11
12#include <iostream>
#include <string>
template <class... Args>
void print(Args... args) {
(std::cout << ... << args) << std::endl;
}
int main(int argc, char *argv[]) {
print(std::string("hello "), "c++ ", "world");
return 0;
}一元折叠表达式空参数包的特殊处理
1
2
3
4template<typename ...Args>
auto sum(Args ...args) {
return (args + ...);
}如果函数模板
sum的实参为空,那么表达式args + ...是无法确定求值类型的- 只有
&&、||和,运算符能够在空参数包的一元折叠表达式中使用 &&的求值结果一定为true||的求值结果一定为false,的求值结果为void()- 其他运算符都是非法的
- 只有
using生命中的包展开,包展开允许出现在using声明的列表内lambda 表达式初始化捕获的包展开 C++ 20
- lambda 表达式按值捕获形参包会有性能问题
- 但是按照引用捕获(除非捕获的变量被立马使用),(如果存在回调函数)被捕获的变量就不在调用栈上了,就会造成 UB
- 闭包逃逸,对象的生命周期就不受程序员控制了
1 | |
当使用到具体函数的时候会难以理解,所以 C++ 20 支持 lambda 表达式初始化捕获的包展开
1 | |
36 typename优化
允许使用 typename 生命模板形参
在 C++ 17 之前,必须使用 class 来声明模板形参,而 typename 是不允许使用的
1 | |
如果将 B 的定义改为 template<template <typename> typename T> struct B{}; 则可能会有编译错误
别名模板
1 | |
A 实际上就是 int 类型而不是模板类型,现在已经没有必要强调必须使用 class 来生命模板形参了
Java 中的type 和class
- 在运行时对类的描述用到的是
class - 如果想描述类型(到底是个什么东西,例如泛型中的
type)就需要用到type
减少 typename 使用的必要性
- 当使用未决类型的内嵌类型时,需要使用
typename明确告诉编译器X<T>::Y可能是函数,也可能是静态变量- 不使用
typename的话编译器会将其当作一个表达式名称
- 在某些情况下是可以不用写
typename- 指定基类和成员初始化
- 从语义上可以判断出来的表达式
- 比如使用
using创建类型别名的时候 using R = typename T::B,typename就可以不用写
- 比如使用
- 上下文仅可能是类型标识的情况
static_cast、const_cast、reinterpret_cast或dynamic_cast等类型转换- 后置返回类型
auto g() -> T::B; - 模板类型参数的默认参数
template <class R = T::B> struct X;
- 全局或者命名空间中简单的声明或者函数定义
- 结构体成员
- 作为成员函数或者 lambda 表达式形参声明